
Finalterm Review & Cheatsheet for
CS 180 Fall 2024 | Intro to Computer Vision and Computational PhotographyAuthor: SimonXie2004.github.io
![]()
Resources
Download Cheatsheet (markdown+images)
Lec2 Capturing Light
Psychophysics of Color: Mean => Hue, Variance => Saturation, Area => Brightness
Image Processing Sequence
- Auto Exposure -> White Balance -> Contrast -> Gamma
White Balancing Algorithms
- Grey World: force average color of scene to grey
- White World: force brightest object to white
Quad Bayer Filters
- Why more green pixels? Because human are most sensitive to green light.
Color Spaces: RGB, CMY(K), HSV, L*a*b* (Perceptually uniform color space)
Image similarity:
- SSD, i.e. L2 Distance
- NCC, invariant to local avg and contrast
\[ \text{NCC}(I, T) = \frac{\sum_{x,y} (I'(x,y) \cdot T'(x,y))}{\sqrt{\sum_{x,y} I'(x,y)^2 \sum_{x,y} T'(x,y)^2}} \]
Lec 3-4: Pixels and Images
Lambertian Reflectance Model:
- \((1-\rho)\) absorbed, \(\rho\) reflected (either diffusely or specularly)
- Diffuse Reflectance: \(I(x) = \rho(x) \cdot \mathbf{S} \cdot \mathbf{N}(x)\)
Image Acquisition Pipeline:
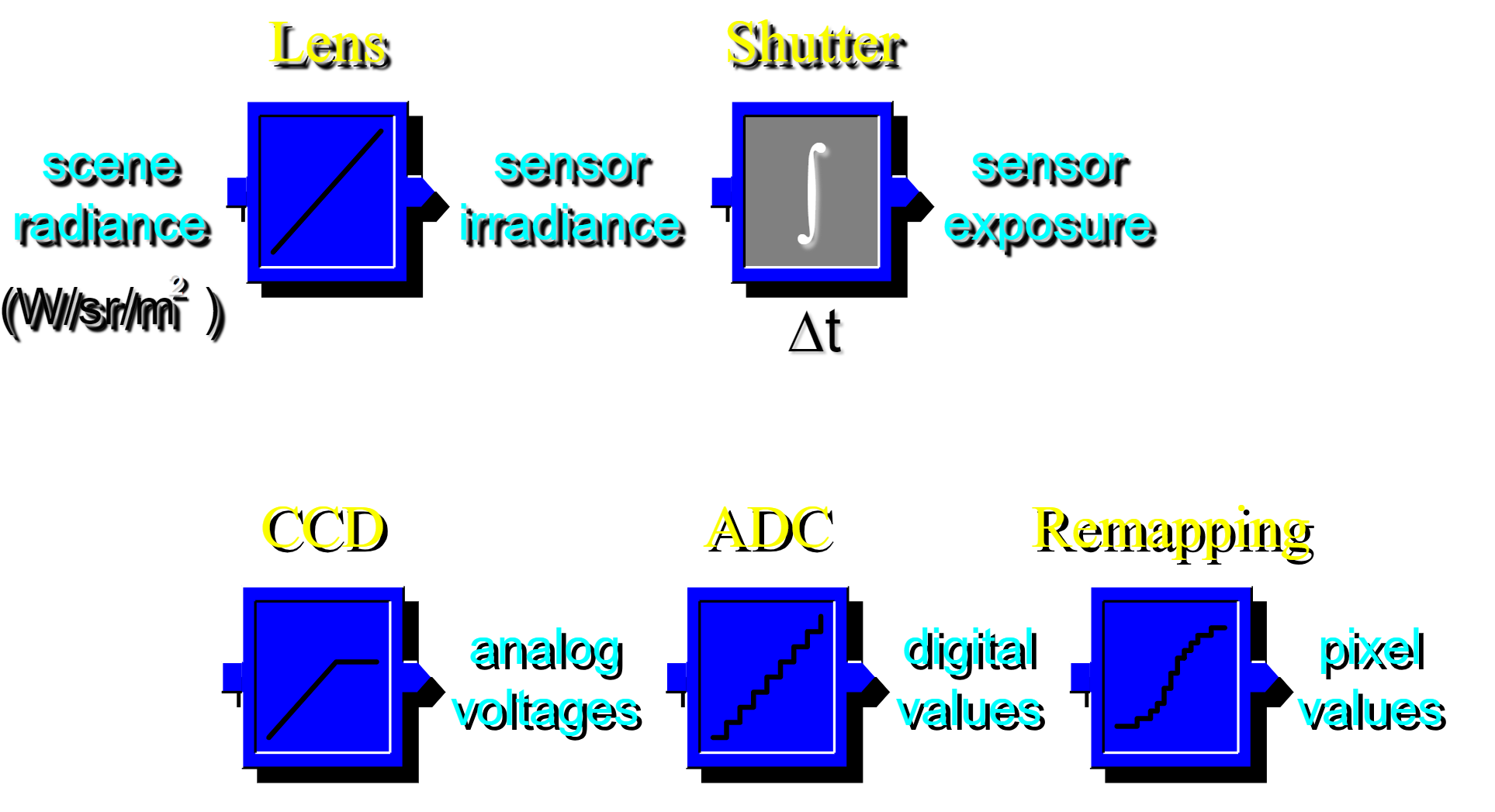
Image Processing: Gamma Correction
- Power-law transformations: \(s = c\cdot r^\gamma\)
- Contrast Stretching: S curve (from input gray level to output)
Histograms Matching and Color Transfer
Image Filter
- Cross Correlation \(C = K \times I\) or \(C(u, v) = \sum_{x=0}^{M-1} \sum_{y=0}^{N-1} I(x, y) \cdot K(x+u, y+v)\)
- Convolution: \(C = K * I\) or \(C(u, v) = \sum_{x=0}^{M-1} \sum_{y=0}^{N-1} I(x, y) \cdot K(x-u, y-v)\)
Example: Gaussian Filter
- Rule of Thumb: Half-Width = \(3\sigma\)
Image Sub-sampling: Must first filter the image, then subsample (Anti-Aliasing)
Image Derivatives: To avoid the effects of noise, first smooth, then derivative (i.e. look for peaks in \(\frac{d}{dx}(f*g)\))
- This leads to LoG or DoG filters
Lec 5: Furrier Transform
- Math:
- Furrier Transform: \(F(\omega) = \int_{-\infty}^{\infty} f(t) e^{-i \omega t} \, dt\)
- Inverse Transform: \(f(t) = \frac{1}{2\pi} \int_{-\infty}^{\infty} F(\omega) e^{i \omega t} \, d\omega\)
- Low pass, High pass, Band pass filters
- Details = High-freq components;
- Sharpening Details: \(f + \alpha (f - f * g) = (1+\alpha)f-af*g = f*((1+\alpha)e-\alpha g)\)
- Remark that \((1+\alpha)e-\alpha g\) is approximately Laplacian of Gaussian.
Lec 6: Pyramids Blending
Gaussian Pyramids and Laplacian Pyramids (Remember to add lowest freq!)
Laplacian Pyramids and Image Blending:

Other image algorithms:
- Denoising: Median Filter
- Lossless Compression (PNG): Huffman Coding
- Lossy Compression (JPEG): Block-based Discrete Cosine Transform
(DCT)
- Compute DCT Coefficients; Coarsely Quantize; Encode (e.g. with Huffman Coding)
Lec 7-9 Affine Transformations
Transform Matrices
- Scaling, Shearing and Translation: \(S = \begin{bmatrix} a & sh_x & t_x \\ sh_y & b & t_y \\ 0 & 0 & 1\end{bmatrix}\)
- Rotation: \(R = \begin{bmatrix} \cos(\theta) & -\sin(\theta) & 0\\ \sin(\theta) & \cos(\theta) & 0 \\ 0 & 0 & 1 \end{bmatrix}\)
Calculating Affine Matrix: \[ \begin{pmatrix} a & b & tx \\ c & d & ty \\ 0 & 0 & 1 \end{pmatrix} \cdot \begin{pmatrix} x_1 & x_2 & x_3 \\ y_1 & y_2 & y_3 \\ 1 & 1 & 1 \end{pmatrix} = \begin{pmatrix} x_1' & x_2' & x_3' \\ y_1' & y_2' & y_3' \\ 1 & 1 & 1 \end{pmatrix} \]
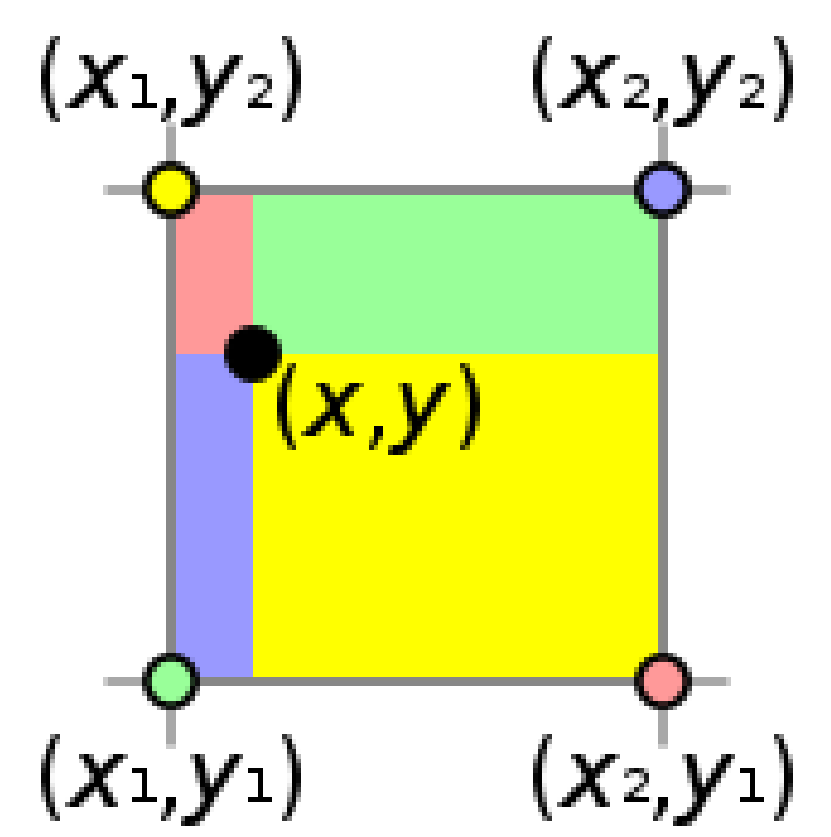
Bilinear Interpolation:
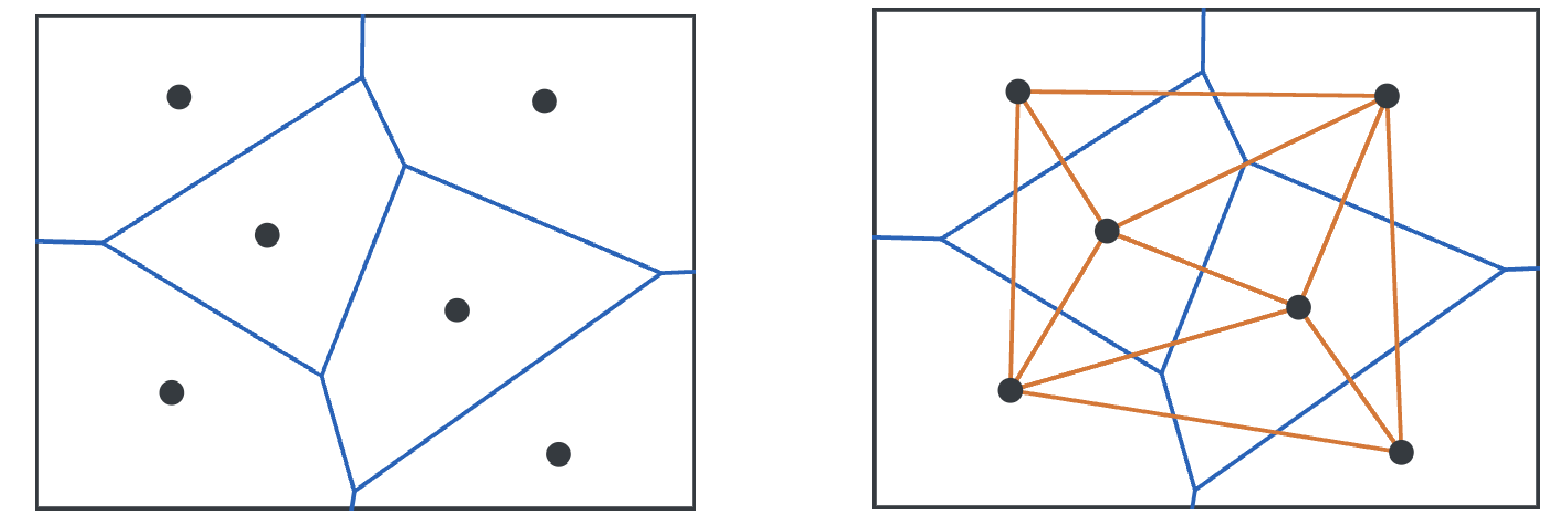
Delaunay Triangulation: Dual graph of Voroni Diagram
Morphing and Extrapolation
Lec 10: Cameras
Pinhole camera model
- Defines Center of Projection (CoP) and Image Plane
- Defines Effective Focal Length as d
Camera coordinate systems
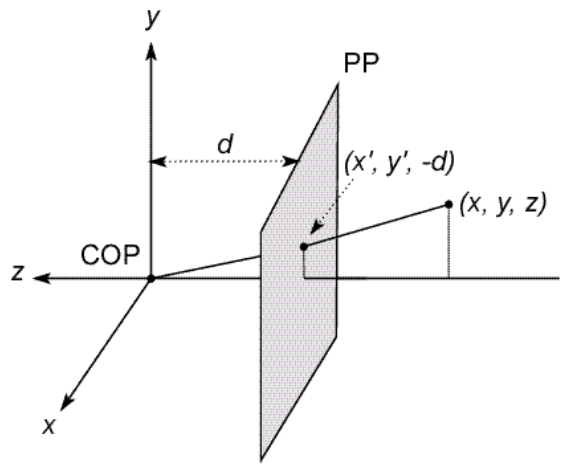
Projection:
Perspective Projection: \((x, y, z) \rightarrow (-d\frac{x}{z}, -d\frac{y}{z}, -d) \rightarrow (-d\frac{x}{z}, -d\frac{y}{z})\)
Orthographic Projection: \((x, y, z) \rightarrow (x, y)\); special case when distance from COP to PP is infinite
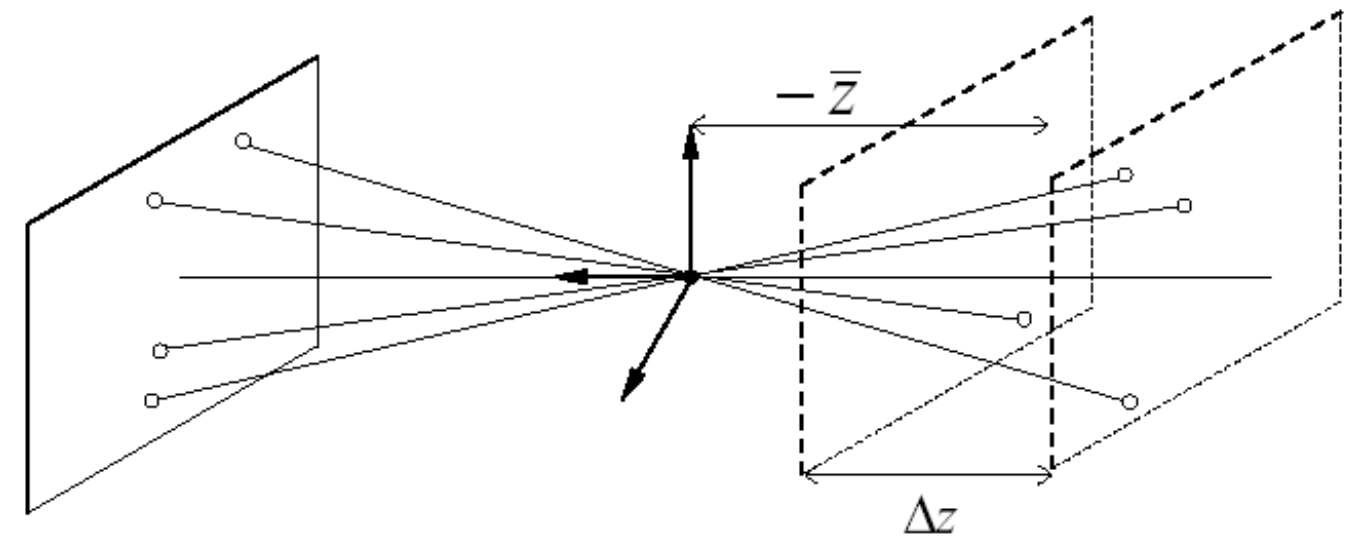
Weak Perspective/Orthographic: if \(\Delta z << -\bar{z}, (x, y, z) \rightarrow (-mx, -my)\) where \(m=-\frac{f}{\bar{z}}\)
Special case when scene depth is small relative to avg. distance from camera
Equivalent to scale first then orthographic project
Spherical Projection: \((\theta, \phi) \rightarrow (\theta, \phi, d)\)
Camera Parameters
Aperture: Bigger aperture = Shallower scene depth, Narrower gate width

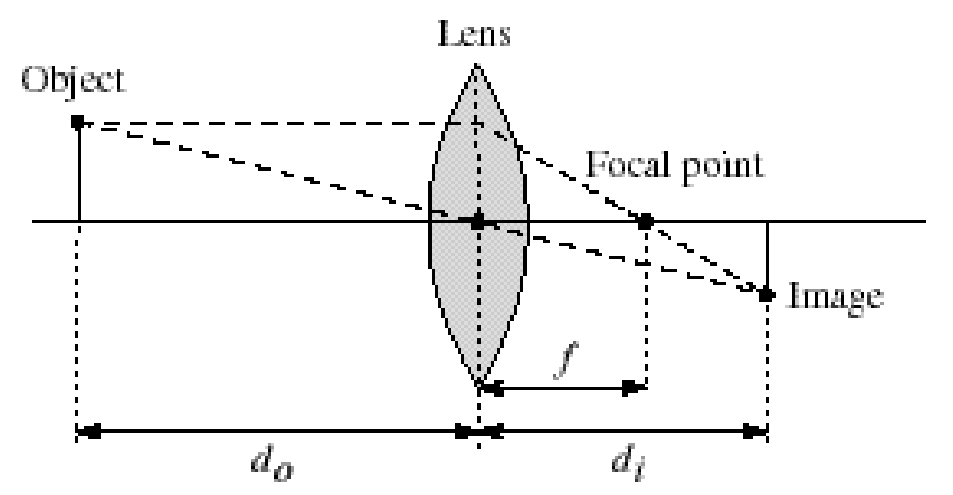
Thin Lenses: \(\frac{1}{d_o} + \frac{1}{d_i} = \frac{1}{f}\)
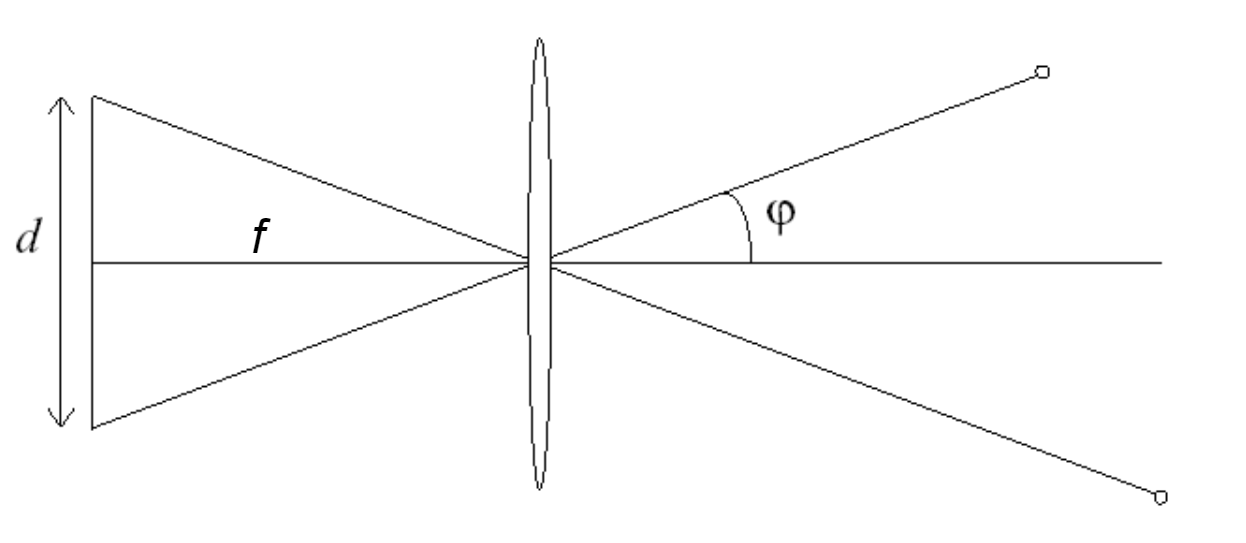
FOV (Field of View): \(\phi = \tan^{-1}(\frac{d}{2f})\)
Exposure & Shutter Speed
- Example: F5.6+1/30Sec = F11+1/8Sec
Lens Flaws
Chromatic Aberration: Due to wavelength-dependent refractive index, modifies ray-bending and focal length
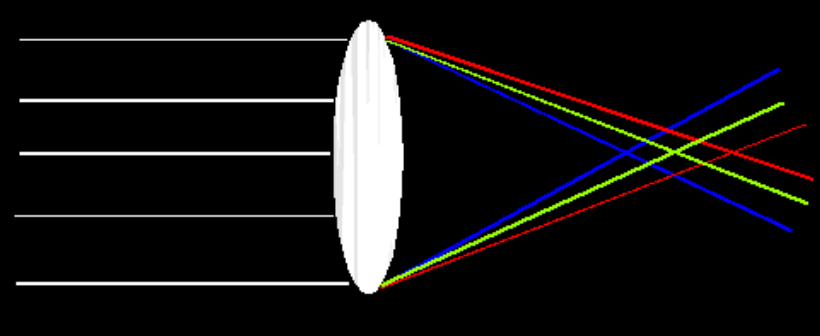
Radial Distortion
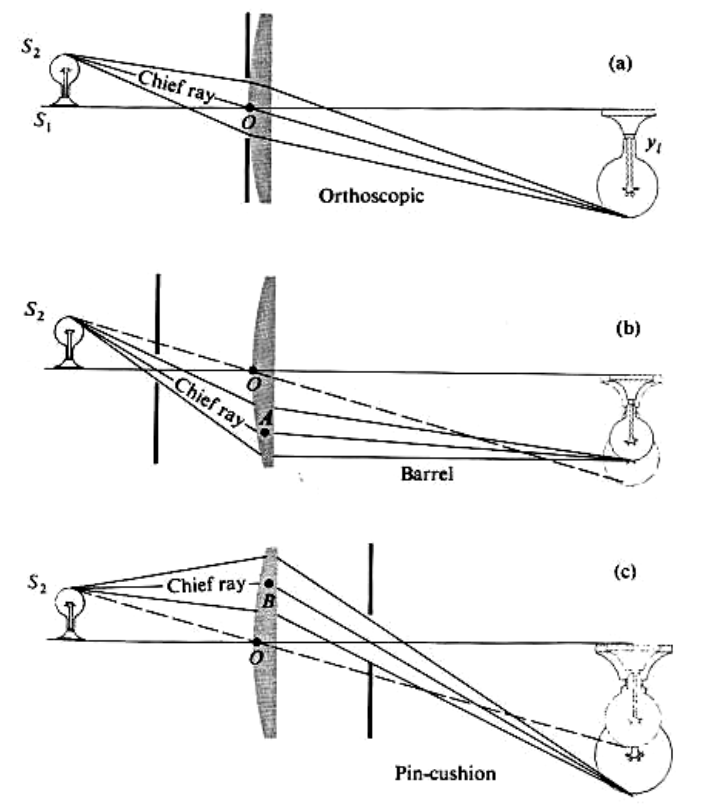
Lec 11: Perspective Transforms
Formula: \[ H = \begin{pmatrix} a & b & c \\ d & e & f \\ g & h & 1 \end{pmatrix} \]
\[ \begin{pmatrix} x_1 & y_1 & 1 & 0 & 0 & 0 & -x_1 x_1' & -y_1 x_1' \\ 0 & 0 & 0 & x_1 & y_1 & 1 & -x_1 y_1' & -y_1 y_1' \\ x_2 & y_2 & 1 & 0 & 0 & 0 & -x_2 x_2' & -y_2 x_2' \\ 0 & 0 & 0 & x_2 & y_2 & 1 & -x_2 y_2' & -y_2 y_2' \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ x_N & y_N & 1 & 0 & 0 & 0 & -x_N x_N' & -y_N x_N' \\ 0 & 0 & 0 & x_N & y_N & 1 & -x_N y_N' & -y_N y_N' \end{pmatrix} \cdot \begin{pmatrix} a \\ b \\ c \\ d \\ e \\ f \\ g \\ h \end{pmatrix} = \begin{pmatrix} x_1' \\ y_1' \\ x_2' \\ y_2' \\ \vdots \\ x_N' \\ y_N' \end{pmatrix} \]
Solution: Least Squares, \(x = (A^TA)^{-1}A^Tb\)
Lec 12-14: Feature Extraction
Feature Detector:
Change in appearance of window W for the shift \([u, v]\) is: \[ E(u, v) = \sum_{(x, y) \in W}[I(x+u, y+v) - I(x, y)]^2 \] Then, we use a First-order Taylor approximation for small motions \([u,v]\): \[ \begin{aligned} I(x+u, y+v) &= I(x, y) + I_x u + I_y v + \text{higher order terms} \\ &\approx I(x, y) + I_x u + I_y v \\ &= I(x, y) + \begin{bmatrix} I_x & I_y \end{bmatrix} \begin{bmatrix} u \\ v \end{bmatrix} \end{aligned} \]
\[ \begin{aligned} E(u, v) &= \sum_{(x, y) \in W} \left[I(x+u, y+v) - I(x, y)\right]^2 \\ &\approx \sum_{(x, y) \in W} \left[I(x, y) + \begin{bmatrix} I_x & I_y \end{bmatrix} \begin{bmatrix} u \\ v \end{bmatrix} - I(x, y)\right]^2 \\ &= \sum_{(x, y) \in W} \left(\begin{bmatrix} I_x & I_y \end{bmatrix} \begin{bmatrix} u \\ v \end{bmatrix}\right)^2 \\ &= \sum_{(x, y) \in W} \begin{bmatrix} u & v \end{bmatrix} \begin{bmatrix} I_x^2 & I_x I_y \\ I_x I_y & I_y^2 \end{bmatrix} \begin{bmatrix} u \\ v \end{bmatrix} \end{aligned} \]
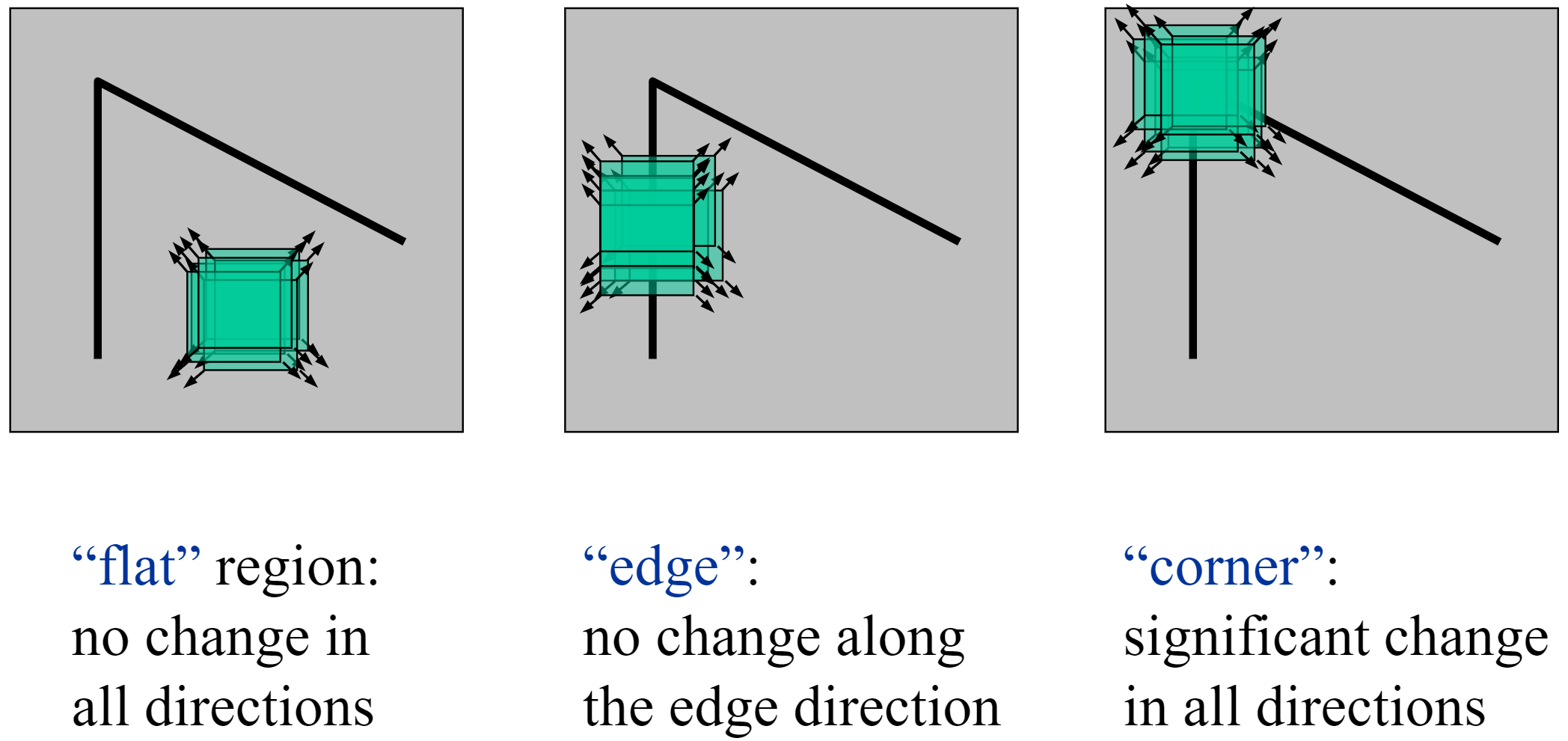
This gives us the second moment matrix M, which is a approximate of local change on images. \[ M = \begin{bmatrix} I_x^2 & I_x I_y \\ I_x I_y & I_y^2 \end{bmatrix} \] Here, we calculate this function value as "corner strength": \[ R = \det(M) - k * \text{tr}(M)^2 \text{ or } \det(M)/\text{tr}(M) \] Remark: for flat areas, both \(\lambda_1, \lambda_2\) are small; for edges, one of the \(\lambda\) is big; for corners, both are big.
Scale Invariant Detection: choose the scale of best corner independently!
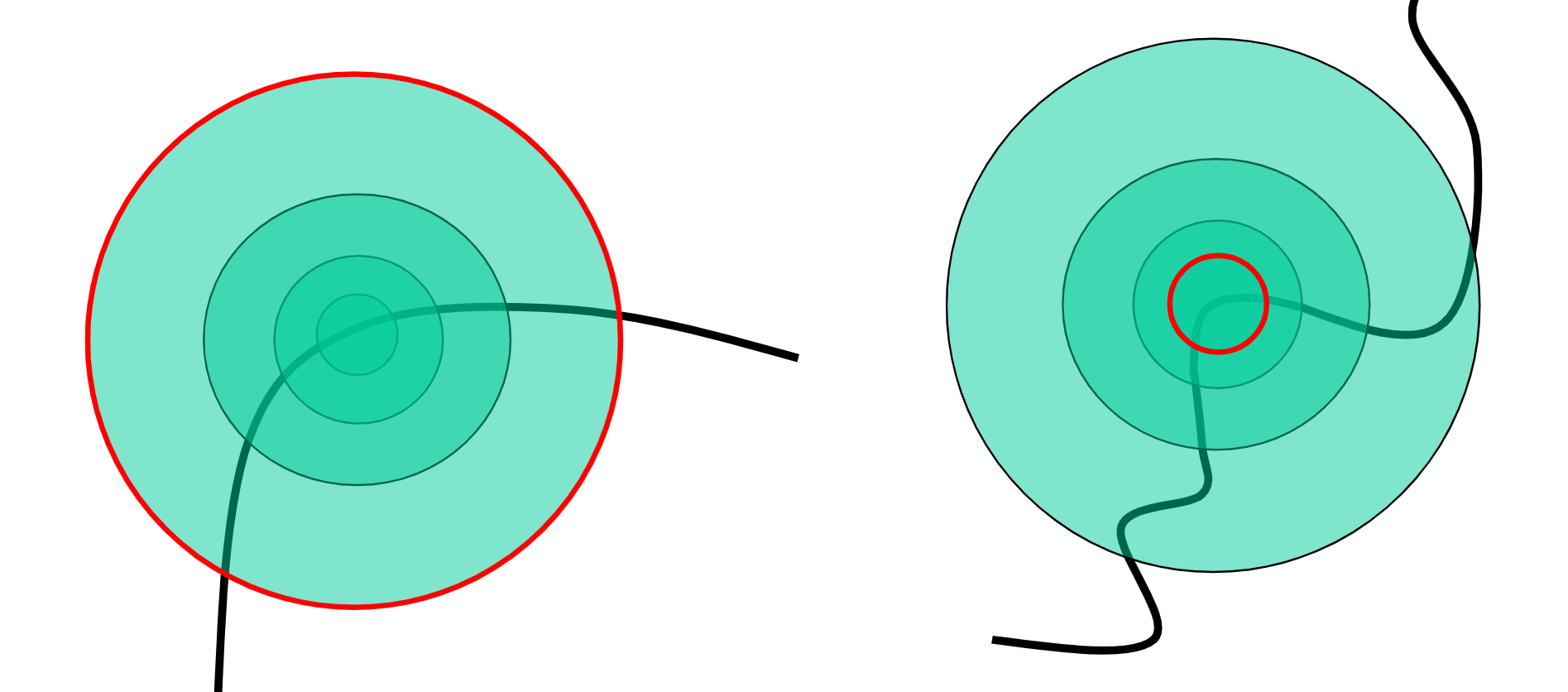
Feature Selection: ANMS

Feature Descriptor (Multi-scale Oriented Patches): 8x8 oriented patch, descripted by (x, y, scale, orientation)
- Maybe normalized by \(I' = (I-\mu)/\sigma\)
Matching Feature:
- Step 1: Lowe's Trick, match(1-NN) - match(2-NN)
- Step 2: RANSAC (random choose 4 points; calc homography; calc outliers; finally select best homography)
Further Techniques: Order images to reduce inconsistencies
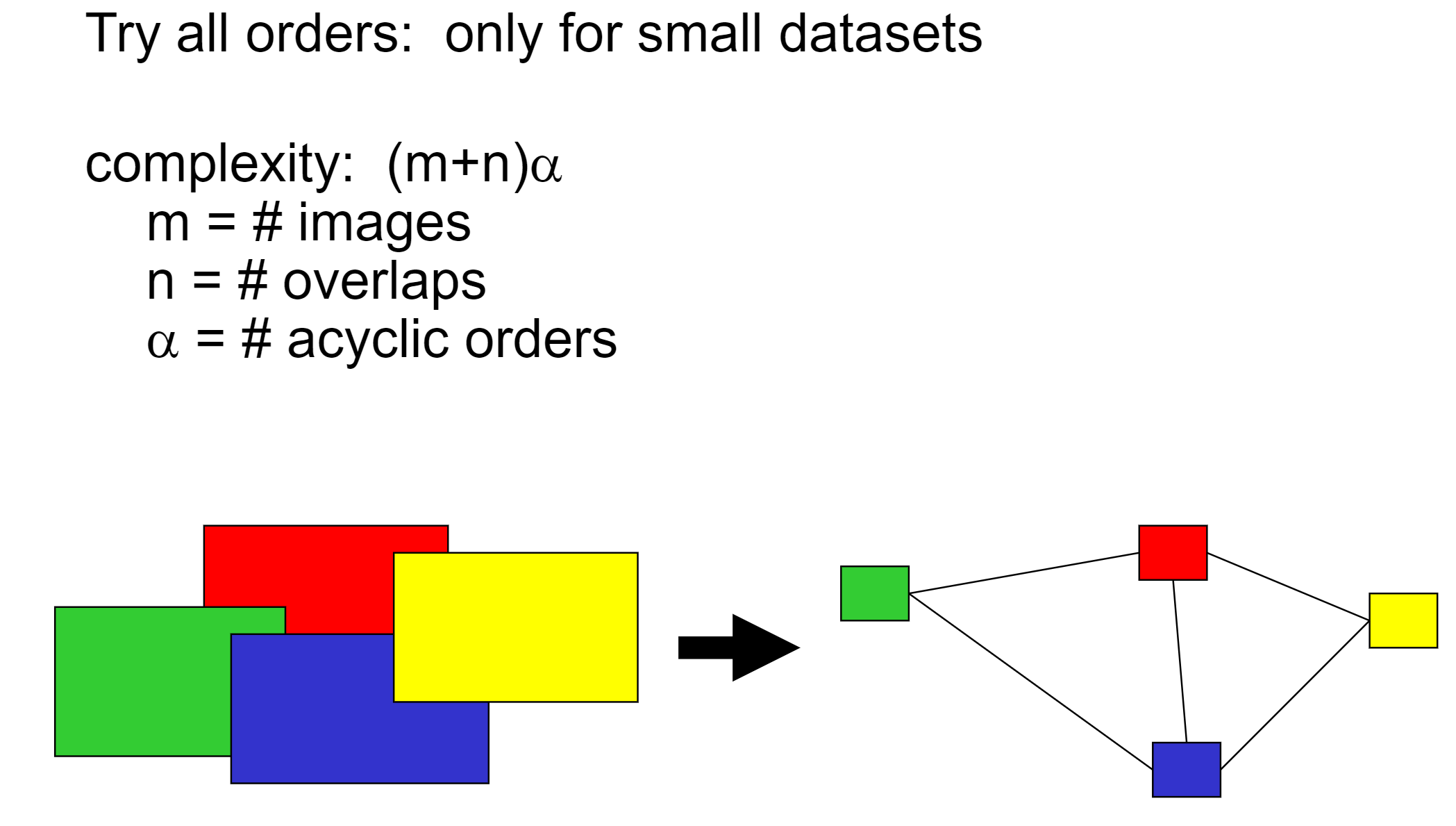
Do the loop: match images - order images - match images - ...
Optical Flow Algorithm \[ 0 = I(x+u, y+v)-H(x, y) \approx [I(x, y) - H(x, y)] + I_xu + I_yv = I_t + \nabla I \cdot [u, v] \] The component of the flow in the gradient direction is determined.
The component of the flow parallel to an edge is unknown.
To have more constraint, consider a bigger window size! \[ \begin{bmatrix} I_x(\mathbf{p}_1) & I_y(\mathbf{p}_1) \\ I_x(\mathbf{p}_2) & I_y(\mathbf{p}_2) \\ \vdots & \vdots \\ I_x(\mathbf{p}_{25}) & I_y(\mathbf{p}_{25}) \end{bmatrix} \begin{bmatrix} u \\ v \end{bmatrix} = - \begin{bmatrix} I_t(\mathbf{p}_1) \\ I_t(\mathbf{p}_2) \\ \vdots \\ I_t(\mathbf{p}_{25}) \end{bmatrix} \] Solve by least square: (Lukas & Kanade, 1981) \[ (A^T A) \mathbf{d} = A^T \mathbf{b} \]
\[ \begin{bmatrix} \sum I_x I_x & \sum I_x I_y \\ \sum I_x I_y & \sum I_y I_y \end{bmatrix} \begin{bmatrix} u \\ v \end{bmatrix} = - \begin{bmatrix} \sum I_x I_t \\ \sum I_y I_t \end{bmatrix} \]
This is solvable when: no aperture problem.
How to make it even better? Do it multi-hierachical!
Lec 15-16: Texture Models
Human vision patterns
- Pre-attentive vision: parallel, instantaneous (~100--200ms), without scrutiny, independent of the number of patterns, covering a large visual field.
- Attentive vision: serial search by focal attention in 50ms steps limited to small aperture.
Order statistics of Textures
- Textures cannot be spontaneously discriminated if they have the same first-order and second-order statistics of texture features (textons) and differ only in their third-order or higher-order statistics.
- First order: mean, var, std, ...
- Second order: co-occurence matrix, contrast, ...
Introduction: Cells in Retina
- Receptive field of a retinal ganglion cell can be modeled as a LoG filter. (Corner Detectors)
- Cortical Receptive Fields -> (Line/Edge Detectors)
- They are connected just like a CNN network.
From Cells to Image Filters: [Filter Banks]
Detects Statistical unit of texture (texton) in real images:
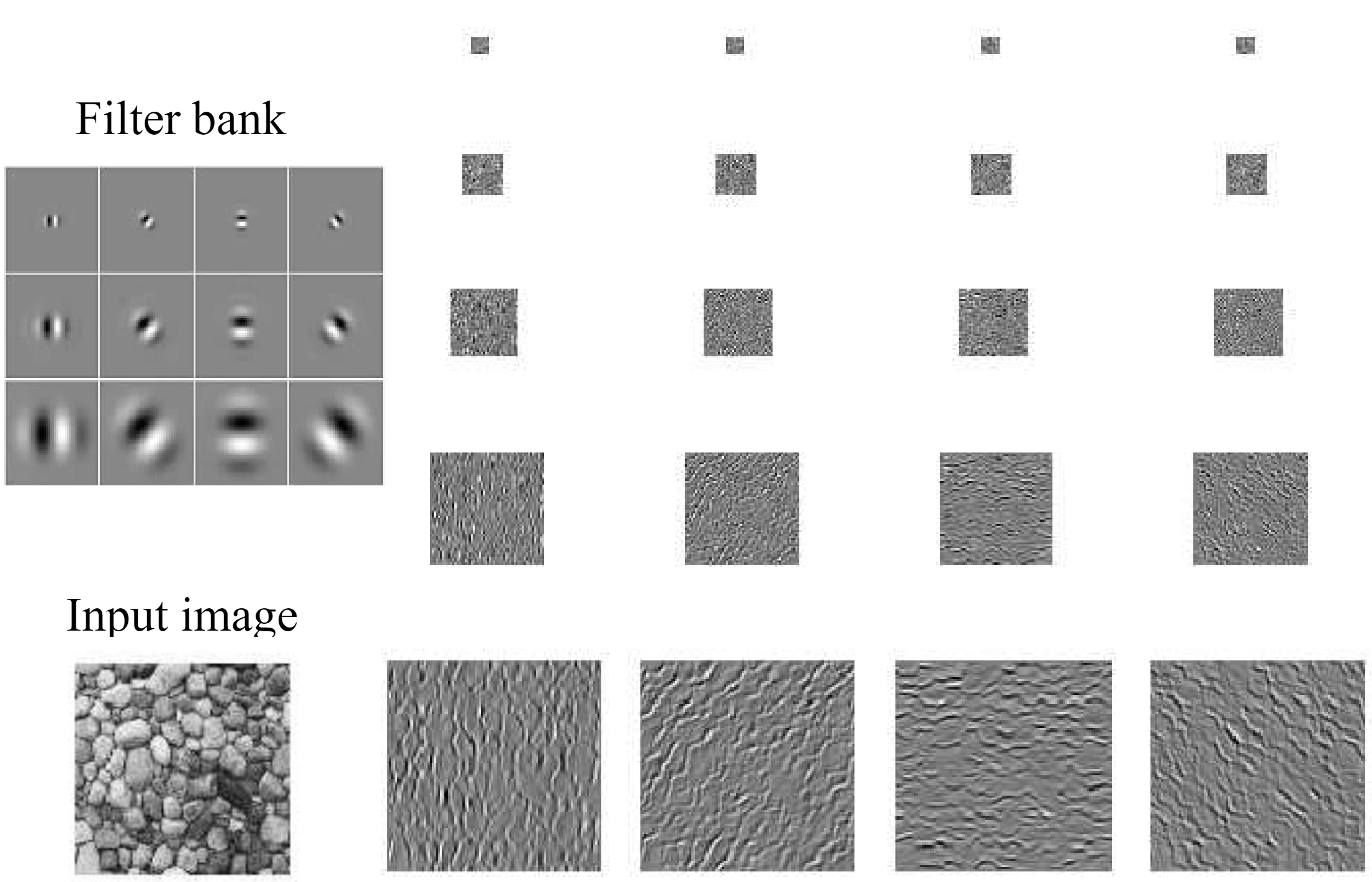
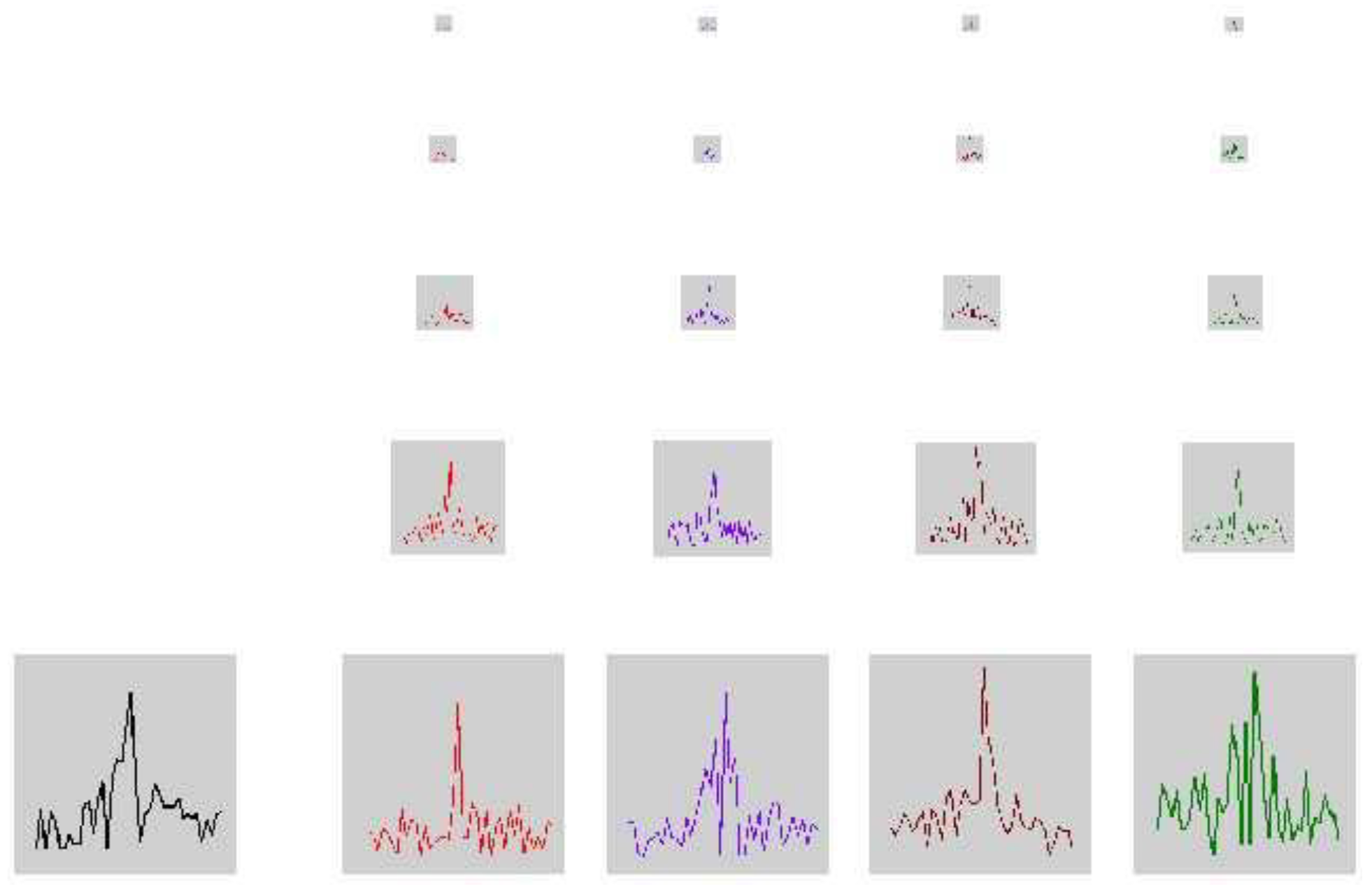

Texton summary: from object to bag of "words"; Preliminaries of CNN
Image Feature Repr:
Code Words -> Hist Matching
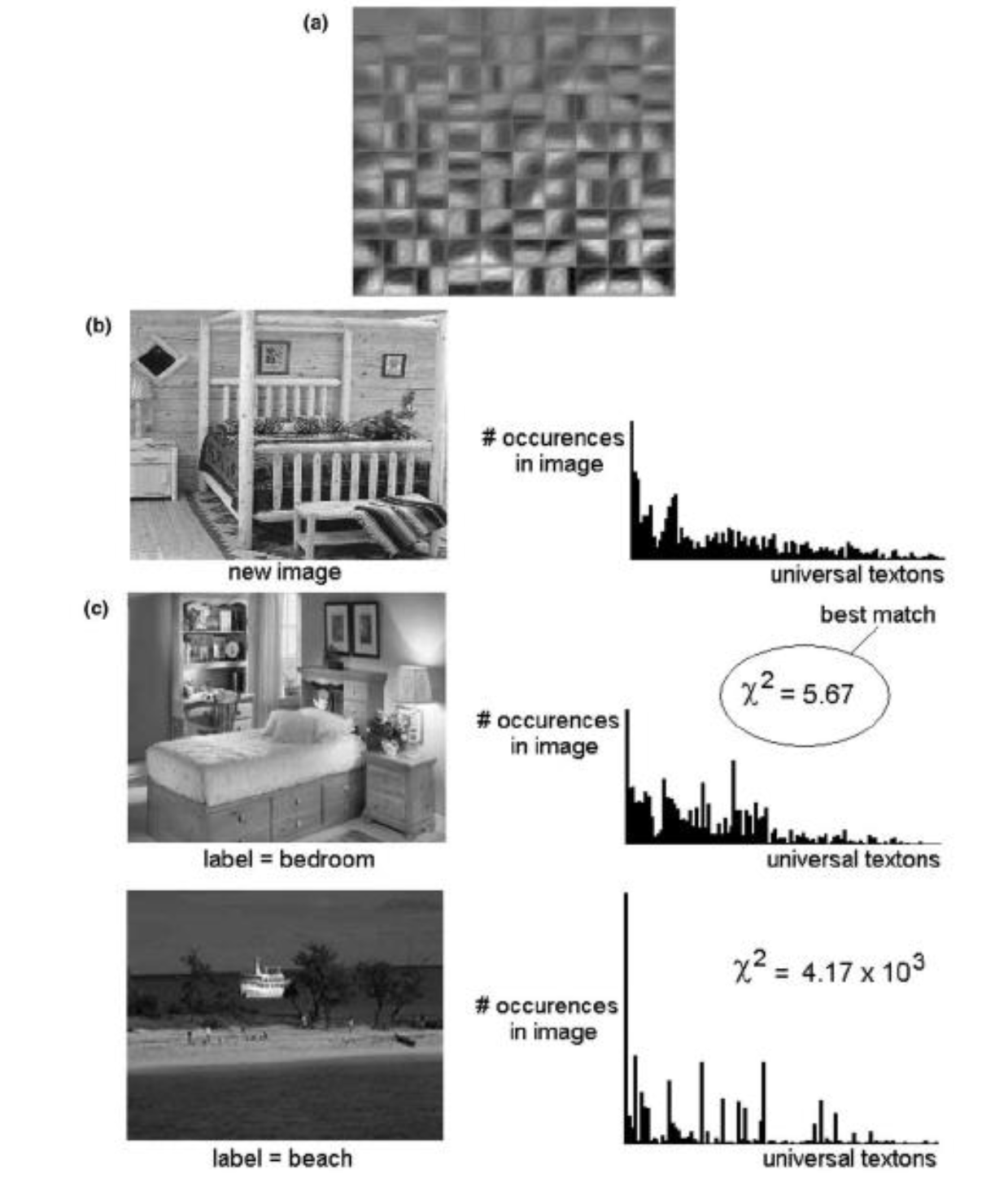
Image-2-Image Translation
- Target: Depths, Normals, Pixelwise-Segmentation/Labelling, Grey-2-Color, Edges-2-Photo, ...
- Wrong exmples:
- Stacking \(2n+1\) convolutions (receptive fields) for \(n\) pixels: too many convolutions!
- Extract NxN patches and independently do CNN: requires too much patches
- Answer: Encoder+Decoder, Convolutions and Pooling
- How about missing details when up-sampling? Copy a high-resolution Version! (U-Net)
- How about loss function? L2 don't work for task: image colorization
- Use per-pixel multinomial classification! (Some what like a bayes net P(label1|pix1), P(label2|pix1), ...)
- \(L(\mathbf{\hat{Z}}, \mathbf{Z}) = -\frac{1}{HW}\sum_{h,w}\sum_{q}\mathbf{Z}_{h,w,q}\log(\mathbf{\hat{Z}}_{h,w,q})\) where q is probability of label q; This is a cross-entropy.
Universal loss for Img2Img Tasks: GAN
Structure: Input -> Generator -> Generated Im; G(x) -> Discriminator -> Loss (Represented as probability; Suppose D(x) is prob that x is fake)
D's task: \(\arg \max_D \mathbb{E}_{x, y}[\log D(G(x)) + \log(1-D(y))]\)
G's task:
Tries to synthesize fake images that fool D: \(\arg \min_G \mathbb{E}_{x, y}[\log D(G(x)) + \log(1-D(y))]\)
Tries to synthesize fake images that fool the best D:
\(\arg \min_G \max_D \mathbb{E}_{x, y}[\log D(G(x)) + \log(1-D(y))]\)
Training Process:
- Sample \(x \sim p_{data}, z \sim p_z\)
- Calc \(L_D\) and backward
- Calc \(L_{G}\) and backward
Example Img2Img Tasks: Labels->Facades, Day->Night, Thermal->RGB, ...
Lec 17-18: Generative Models
Revision of an Early Vision Texture Model:
- Select \(x \sim p_{data}; z \sim p_z\) (z is usually noise)
- Multi-scale filter decomposition (Convolve both images with filter bank)
- Match per channel histograms (from noise to data)
- Collapse pyramid and repeat
Make it better?
- Match joint histograms of pairs of filter responses at adjacent spatial locations, orientations, scales, ...
- Optimize using repeated projections onto statistical constraint surfaces.
Make it more modern: Use CNN to do texture synthesis
Previously, we use histograms to describe texture features. Now, we use Gram Matrices on CNN Features as texture features.
Define CNN output of some layer as: \[ F_{N\times C} = [f_1, f_2, \dots, f_N]^T \] We have: \[ G = FF^T = \begin{bmatrix} \langle f_1, f_1 \rangle & \cdots & \langle f_1, f_N \rangle \\ \vdots & & \vdots \\ \langle f_N, f_1 \rangle & \cdots & \langle f_N, f_N \rangle \end{bmatrix} \] where \[ \langle f_i, f_j \rangle = \sum_k F_{ik} F^T_{kj} \] This describes the correlation of image feature \(f_i\) and \(f_j\), which are both length C (channel) vectors.
Define loss as: \[ L_{\text{style}} = \sum_l \frac{1}{C_l^2 H_l^2 W_l^2} \| G_l(\hat{I}) - G_l(I_{\text{style}}) \|_F^2 \]
Pipeline for Texture Synthesis:
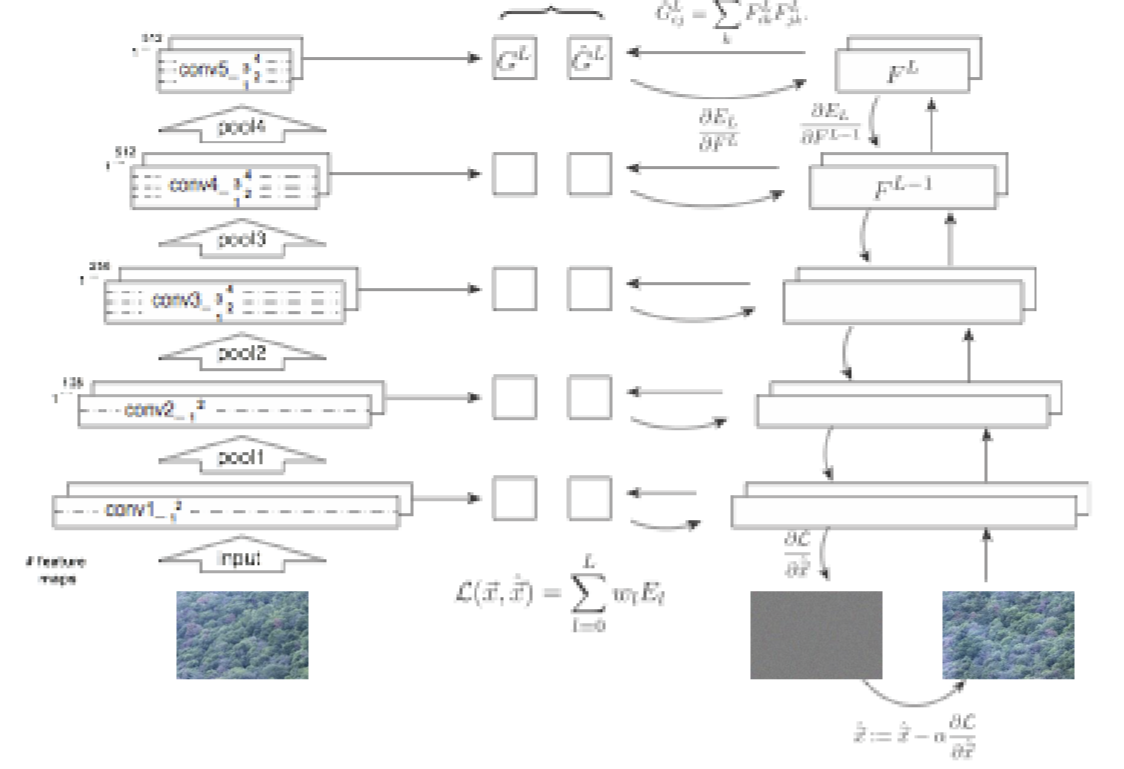
Remark: The CNN used here is just a pre-trained texture-recognition CNN network, where VGG-16 or VGG-19 nets can be used.
Basically, select any CNN network that is trained to map from image to label (e.g. "dog") will recognize features totally fine. They are already trained on ImageNet dataset.
Use CNN to do artistic style transfer
Loss Function Design:
\[ L_{\text{style}} = \sum_l \frac{1}{C_l^2 H_l^2 W_l^2} \| G_l(\hat{I}) - G_l(I_{\text{style}}) \|_F^2 \]
\[ L_{\text{content}} = \frac{1}{2} \sum_{i,j} \left( F_{i,j}^{\text{generated}} - F_{i,j}^{\text{content}} \right)^2 \]
Pipeline:
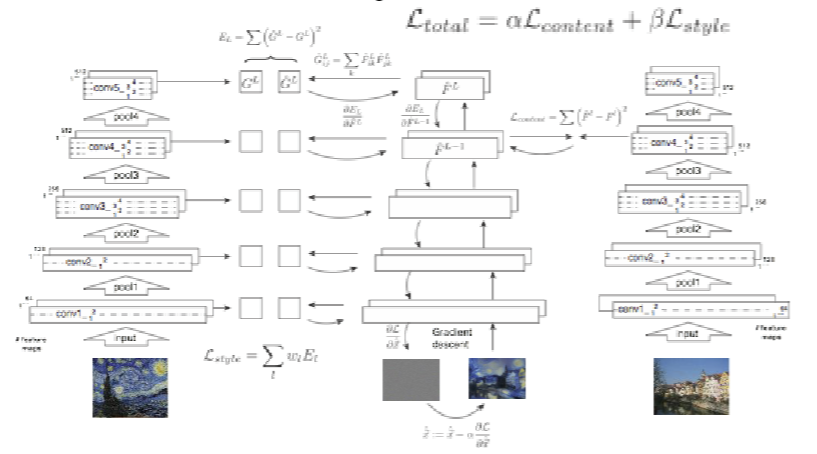
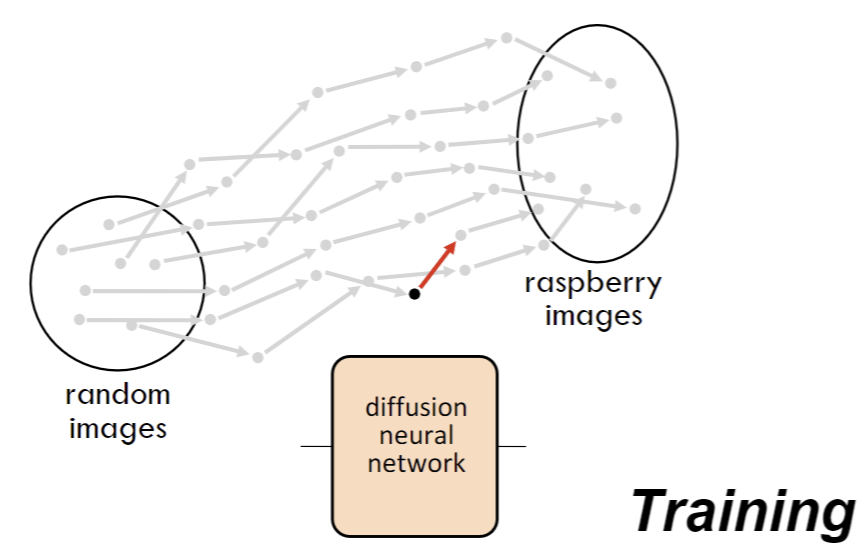
Diffusion
Training / Inference(Forward):
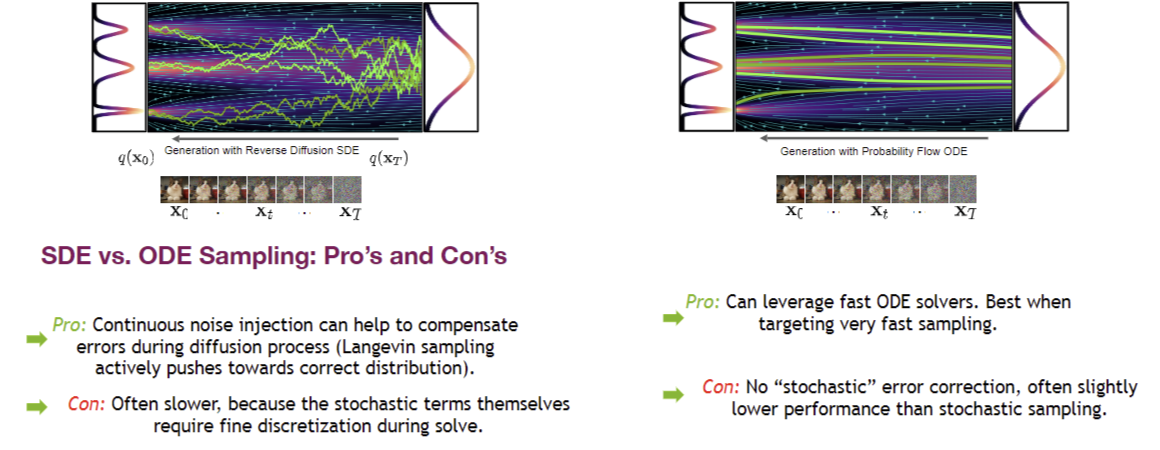
Sampling methods: DDPM vs DDIM
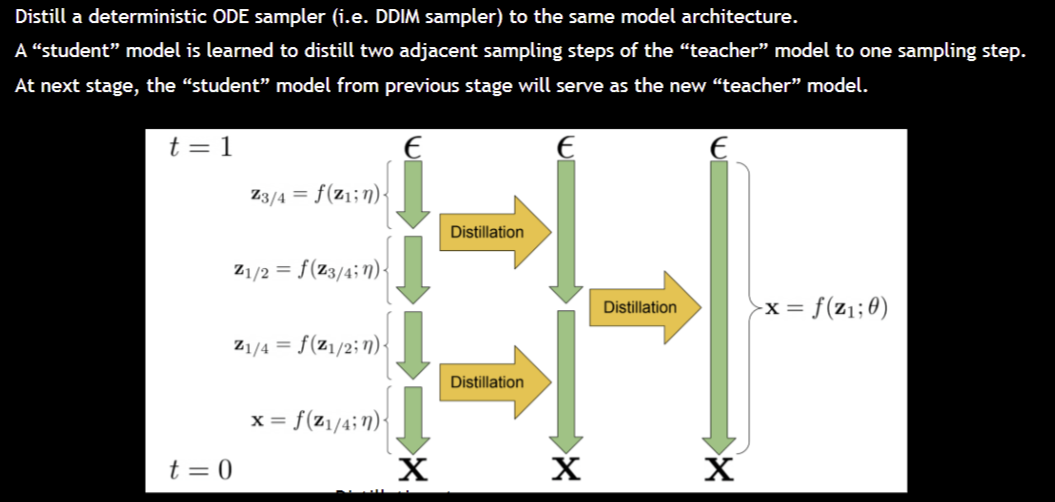
Make sampling faster? Distilation!
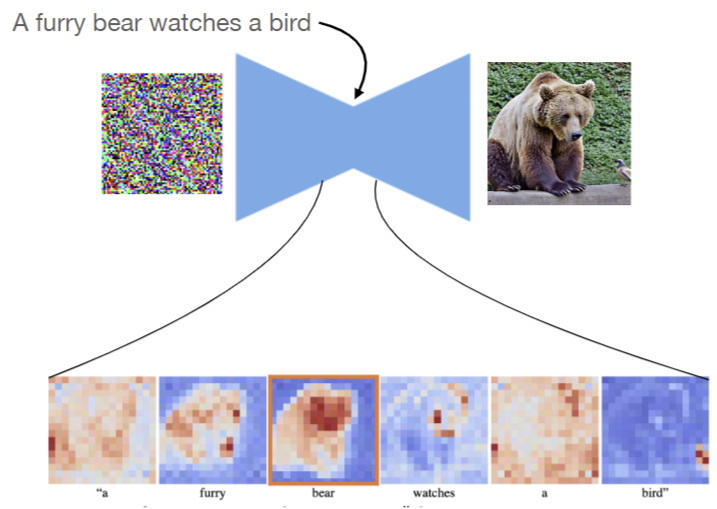
Editing desired area? Generate a mask that a word corresponds to!
Common Image Generating Models:
- Parti: self-regressive model; generates images block by block
- Imagen: Diffusion
- Dalle-2: Parti + Imagen
Lec 19: Sequence Models
Shannon, 1948: N-gram model; Compute prob. dist. of each letter given N-1 previous letters (Markov Chain)
Video Textures, Sig2000:
Compute L2 distance \(D_{i, j}\) for between all frames
Markov Chain Repr
Transition costs: \(C_{i \rightarrow j} = D_{i+1, j}\); Probability Calculated as: \(P_{i \rightarrow j} \propto \exp(-C_{i \rightarrow j} / \sigma^2)\)
Problem: Preserving Dymanics? Solution: Use previous N frames to calculate cost.
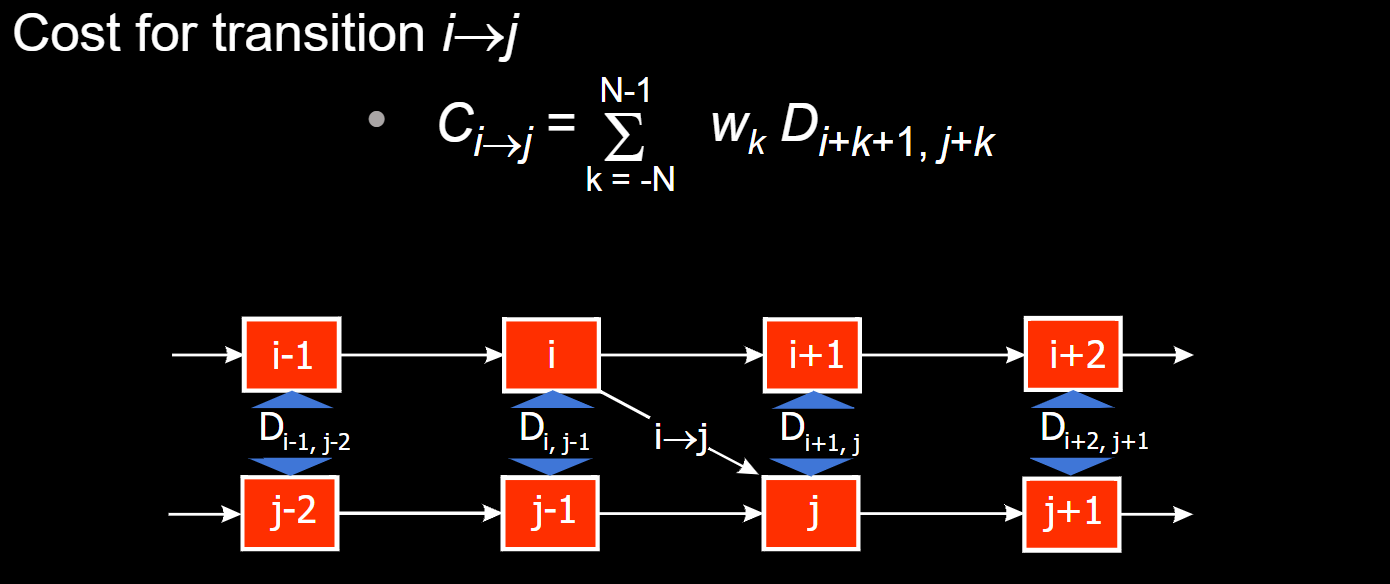
Problem: Control video texture speed? Solution: change the weighted sum parameters of previous N costs.
Problem: User control? (e.g. fish chasing mouse pointer)? Solution: add user control term \(L = \alpha C + \beta \text{angle}\)
- Maybe need to precompute future costs for a few angles
Efros & Leung Texture Synthesis Algorithm:
(Bigger window size is better, but requires more params!)
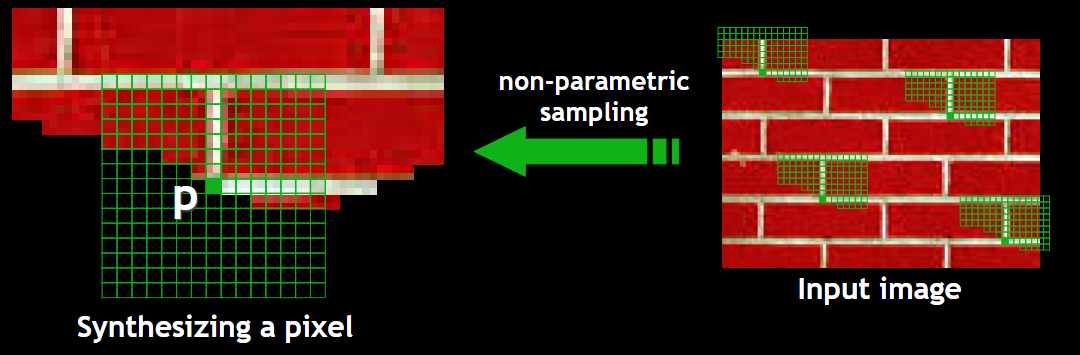
Image Analogies Algorithm: Process an image by example (A:A' :: B:B') (Siggraph 2001)
- Compare area of pixels (e.g. 10*10) from img A and B.
- Find the best match, then copy some smaller area of pixels (e.g. 3*3) from imgA' to imgB'
- Remark: Neurips 2022, later method uses VQ-GAN and MAE to finish this
Word Embedding (word2Vec, GloVe)...
Attention + Prediction: Word sequence tasks
- possible explanation: different layers (attention+prediction) works for different functions (syntax, semantics, ...)
Similar methods for image generation: treat image as blocks of pixels and generate in order (Parti)
Lec 20: Single View 3D Vision Geometry
Projecting points: use homo coords \((sx, sy, s)\)
Projecting lines:
A line in the image correspond to a plane of rays through origin.
Computing vanishing points:
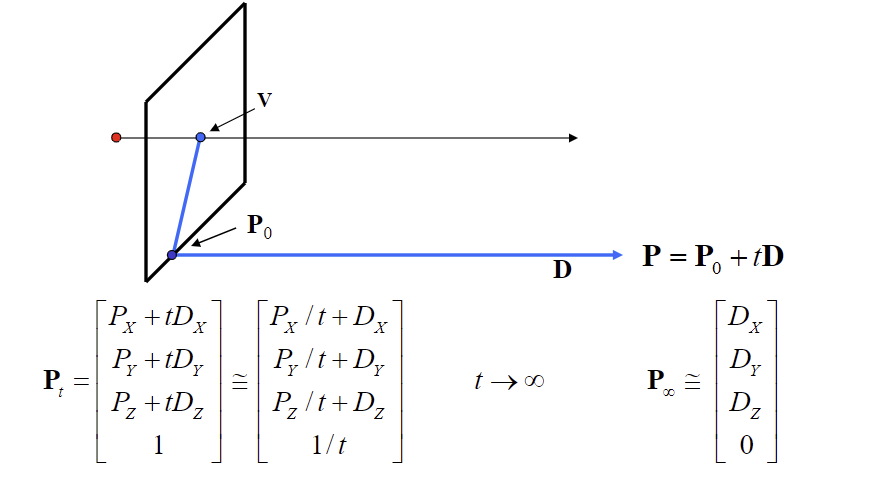
Remark1: Any two parallel lines have same vanishing point.
Remark2: An image may have more than one vanishing point.
The union of all vanishing points is the horizon line (vanishing line)
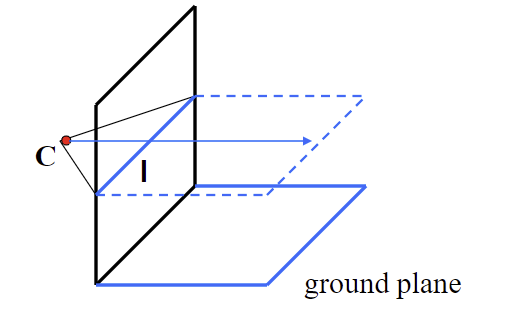
Different planes define different vanishing lines
Compute from two sets of parallel lines on the ground plane
All points at same height as C projects to I
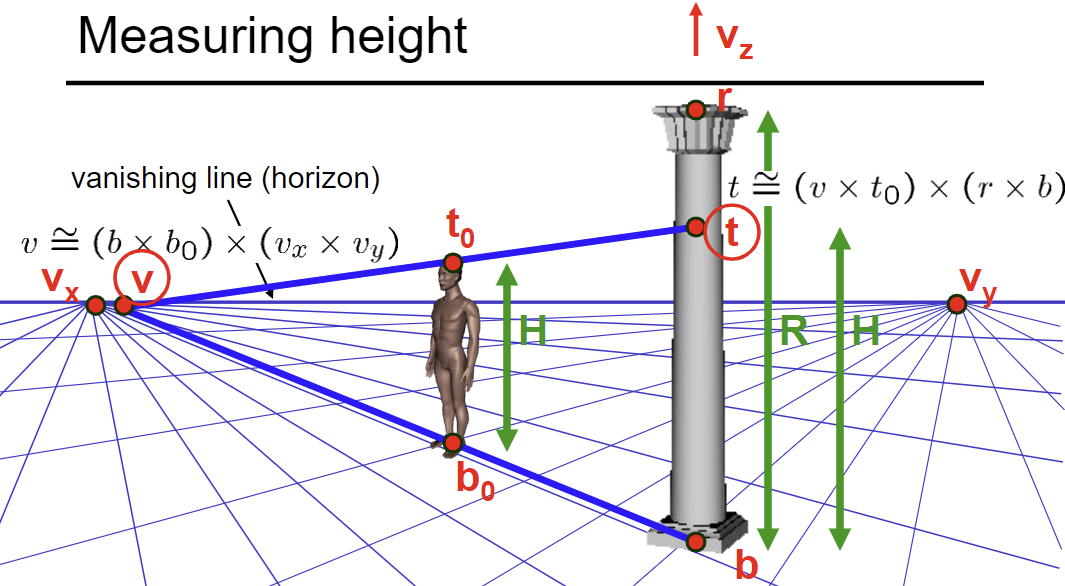
3D from single image

Find world coordinates (X, Y, Z) for a few points.
Define ground plane (Z=0)
Detecting lines in image? Use Hough Transform
Compute points (X,Y,0) on that plane (by homography)

Compute the heights Z of all other points (using perspective clues)
Lec 21: Multiple View 3D Geometry
Disparity Map * Depth Map = Constant.
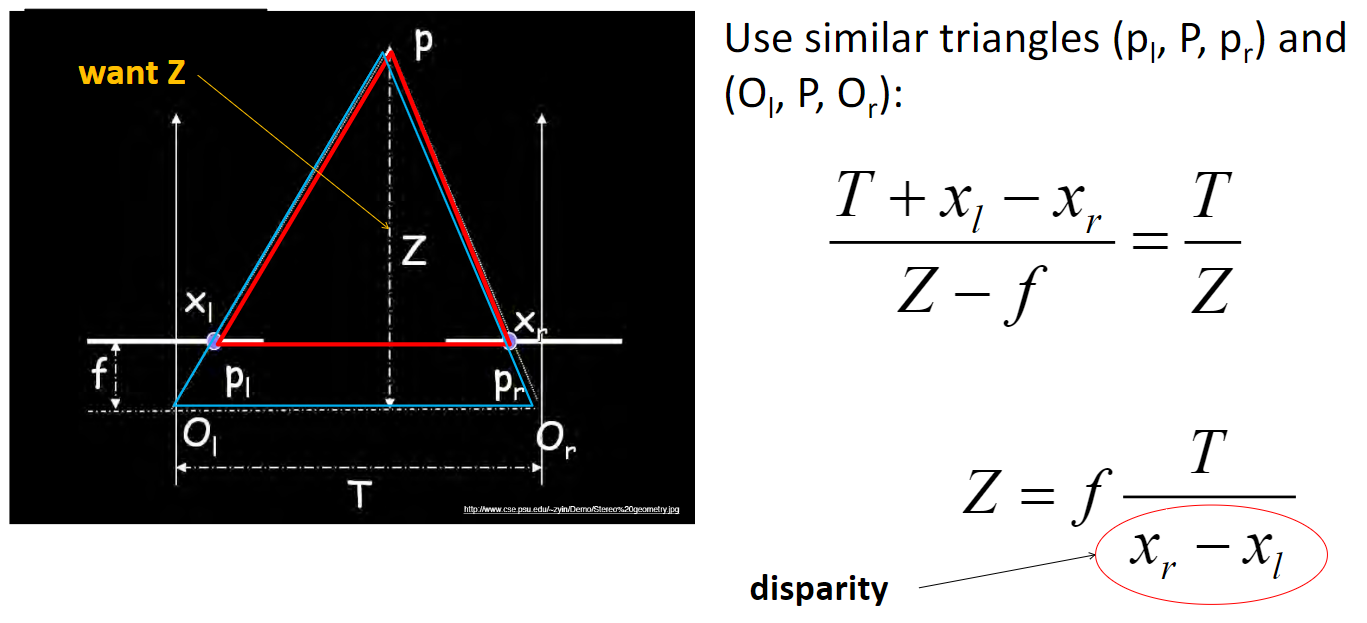
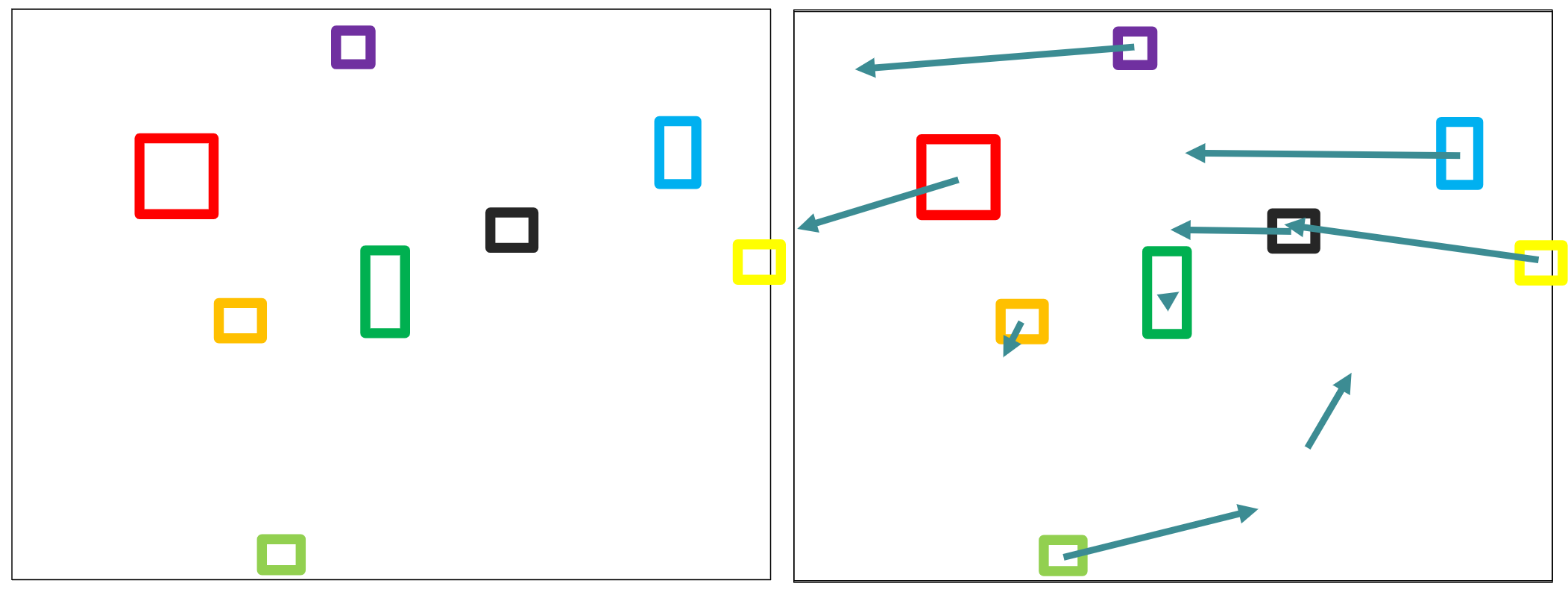
Correspondence problem:
Calculate Epipolar; Match along epipolar line
Effect of window size: want window large enough to have sufficient intensity variation, yet small enough to contain only pixels about the same disparity
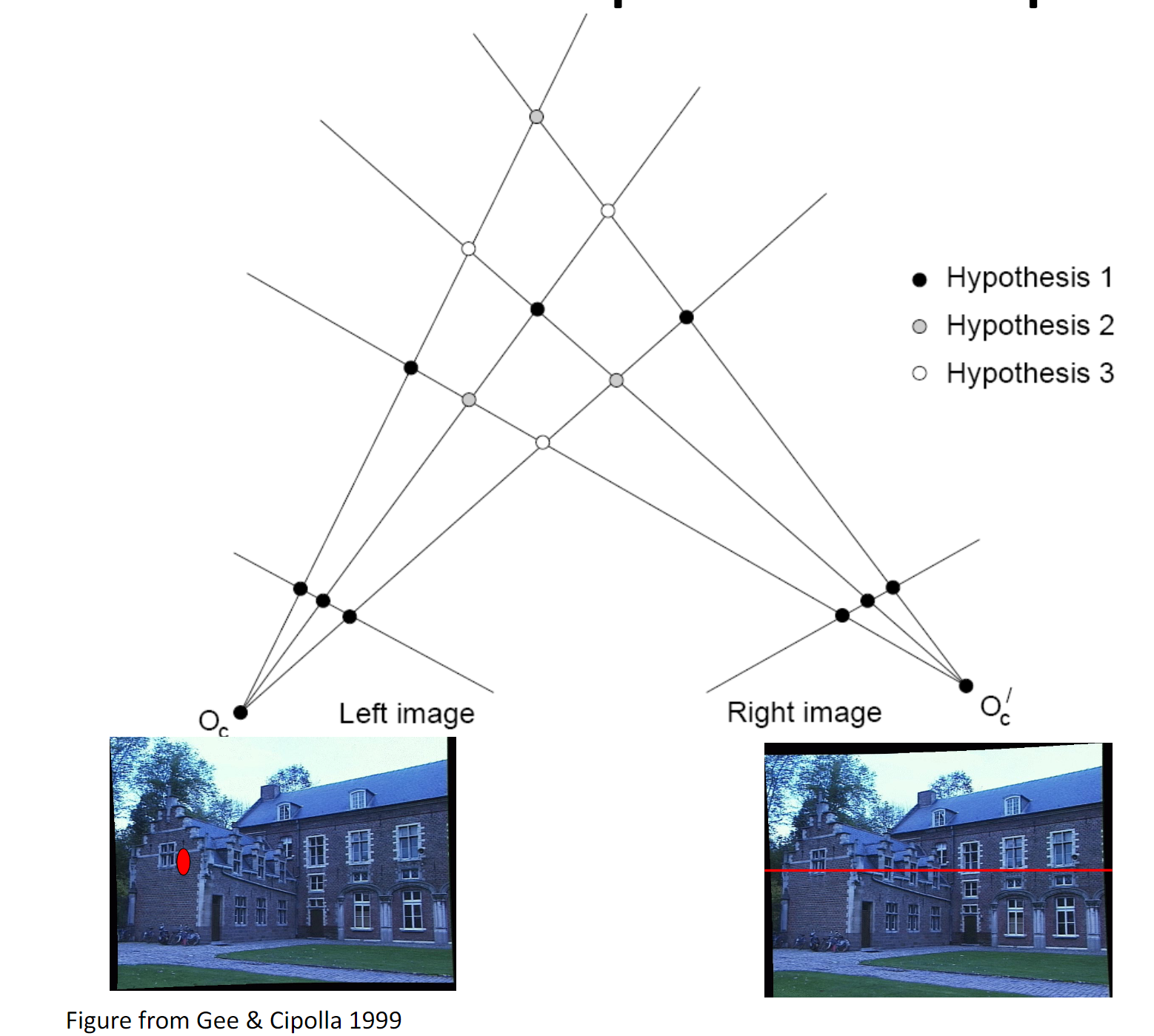
Feature Correspondence Pipeline:
- Detect Keypoints; 2. Extract SIFT at each keypoint; 3. Finding correspondences
- ALSO: CNN-based stereo matching / depth(disparity) estimation
- Feature Extraction; Calculate Cost Volume (pixel i's matching cost at disparity d); Cost Aggregation; Disparity Estimate (simple argmin)
Camera Projection Model: \(x_{uv} = K[R, t]X_{xyz}\) where \([R, t]\) is w2c matrix
Calibrate a Camera? Learning Problem. (use least square; just like solving homography)
Once we have solved M, decomposite it to K*R using RQ decomposition.

Epipolar Geometry:
Introduction: Camera may have rotation, along with translation
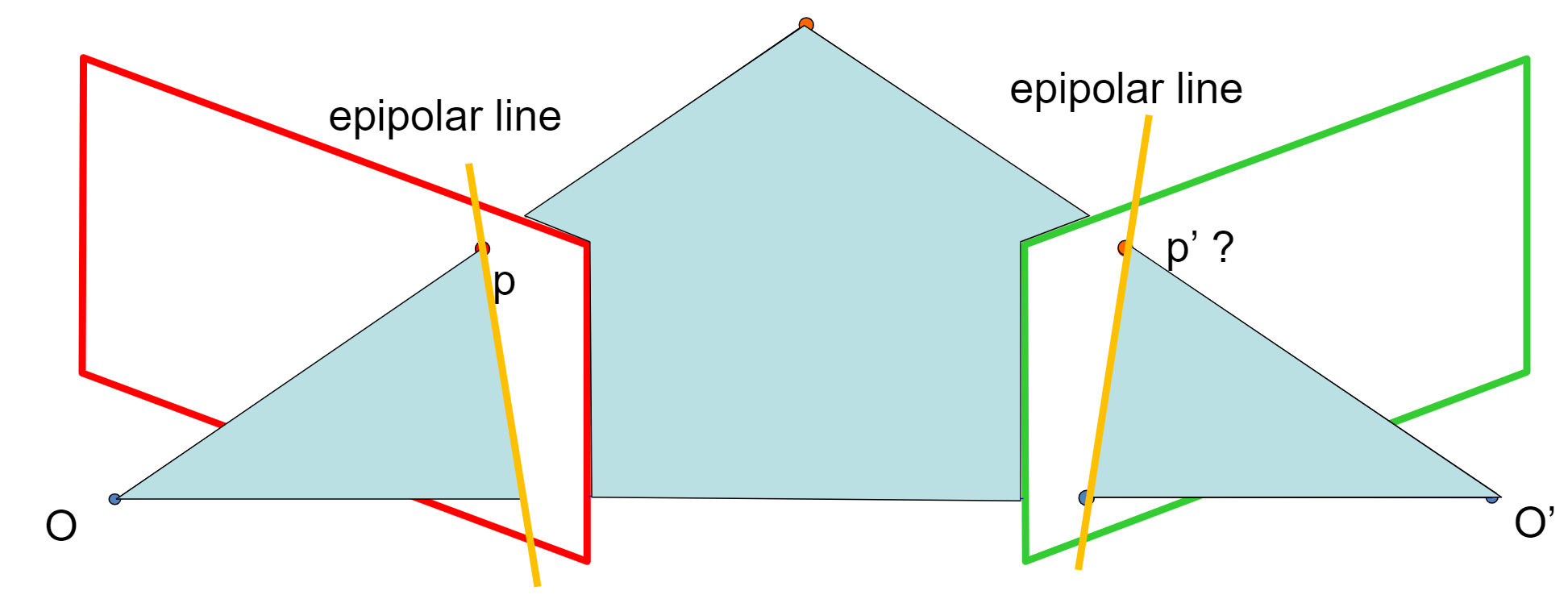
Definitions
Baseline: the line connecting the two camera centers
Epipole: point of intersection of baseline with the image plane
Epipolar plane: the plane that contains the two camera centers and a 3D point in the world
Epipolar line: intersection of the epipolar plane with each image plane
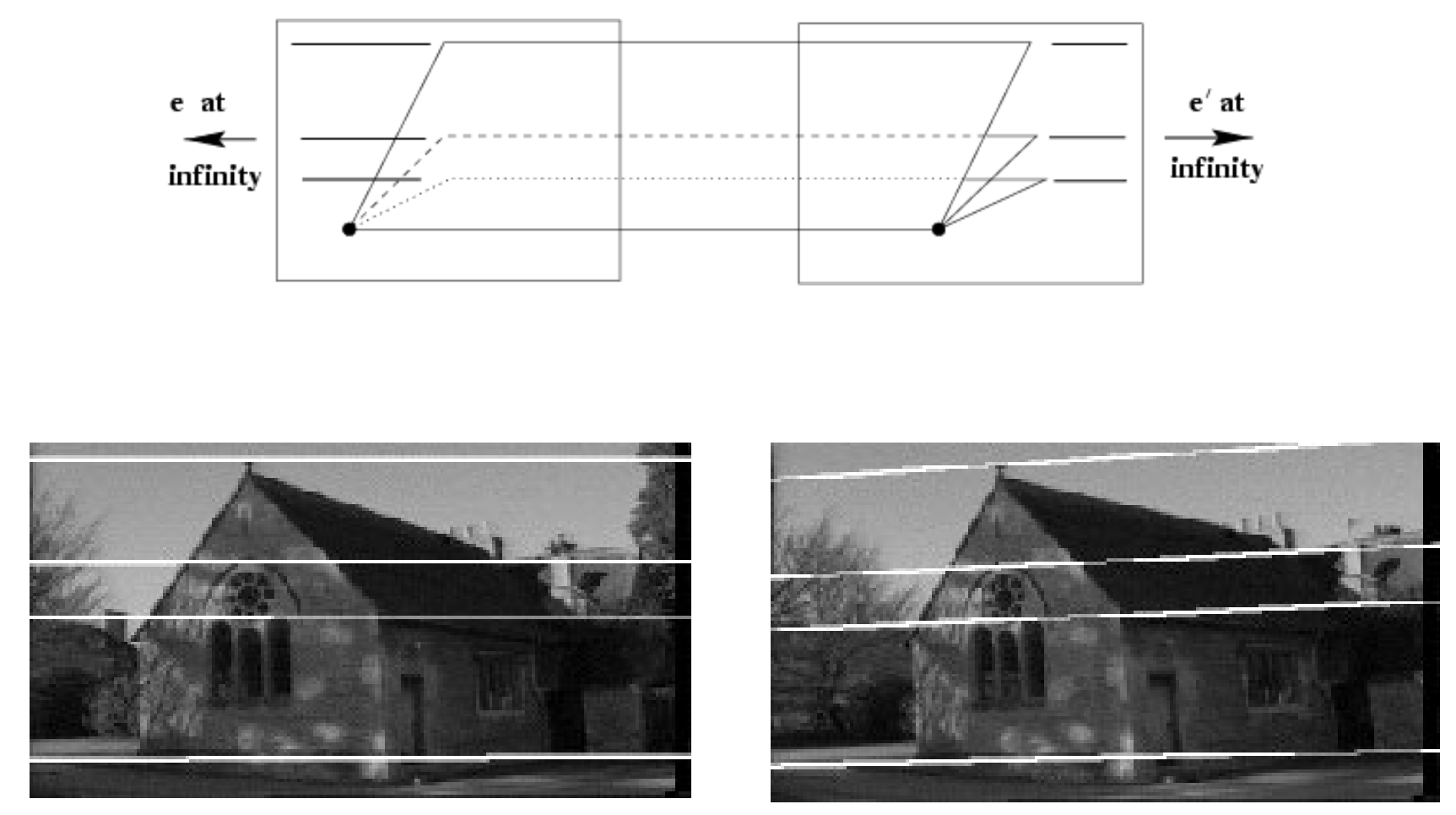
EXAMPLE 1: parallel movement
EXAMPLE 2: forward movement

Usage: Stereo image rectification
Reproject image planes onto a common plane parallel to the line between optical centers
Then pixel motion is horizontal after transformation
Two homographies (3x3 transforms), one for each input image reprojection
Calculations: How to express epipolar constraints? (When camera is calibrated)
Answer: use Essential Matrix

Proof: \(X'=RX+T; T \times X' = T \times RX + T \times T = T \times RX; X' \times (T \times X') = 0\)
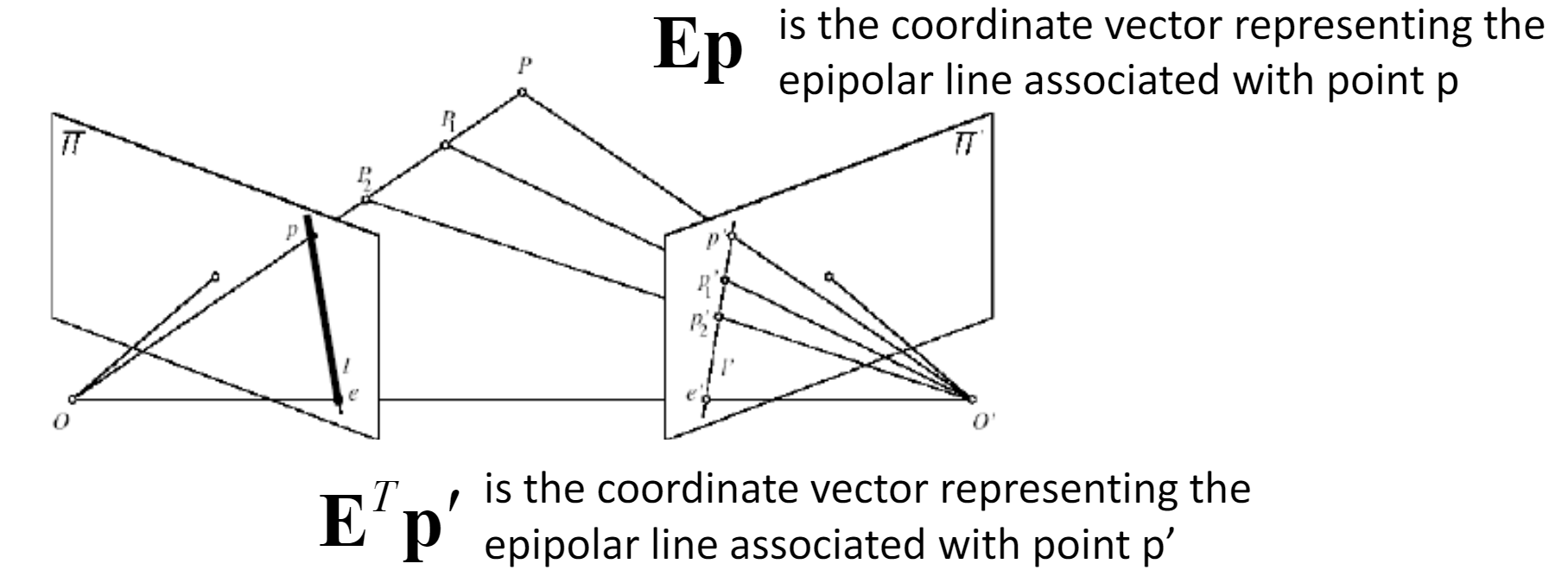
Properties of \(E=T_xR\):
- $ Ex' $ is the epipolar line associated with $ x' $ ($ l = E x' $)
- $ E^Tx $ is the epipolar line associated with $ x $ ($ l' = E^T x $)
- $ E e' = 0 $ and $ E^T e = 0 $
- $ E $ is singular (rank two)
- $ E $ has five degrees of freedom (3 for rotation $ R $, 2 for translation $ t $ since it is up to a scale)
Calculations: How to express epipolar constraints? (When camera is un-calibrated)
Answer: Estimate the Fundamental matrix.
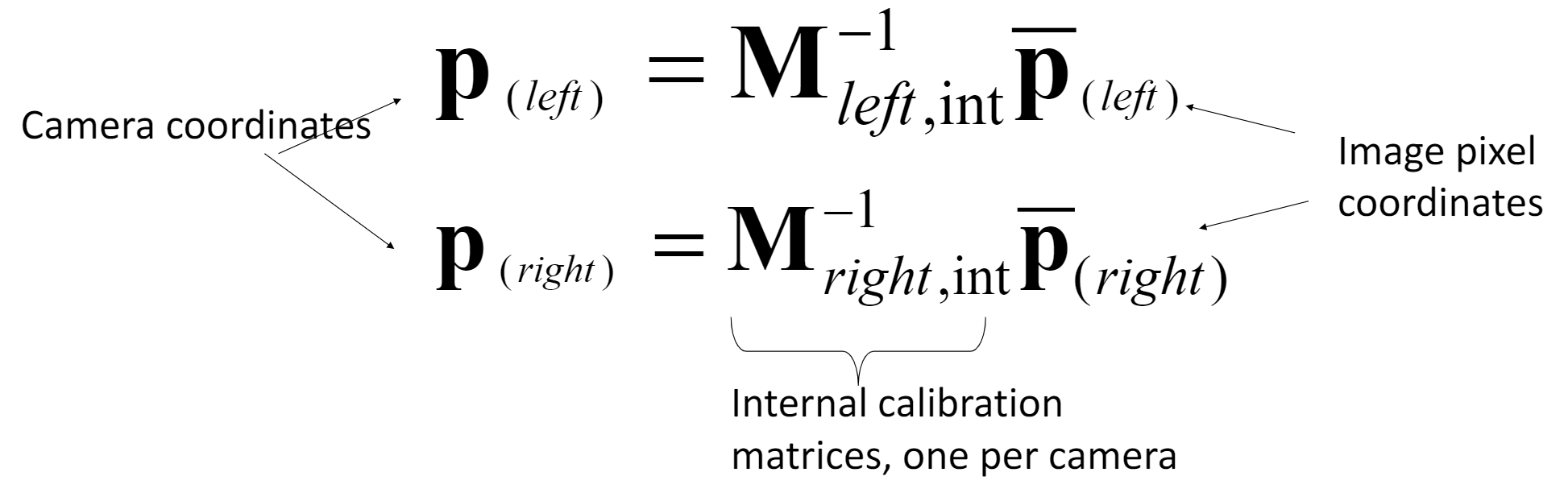
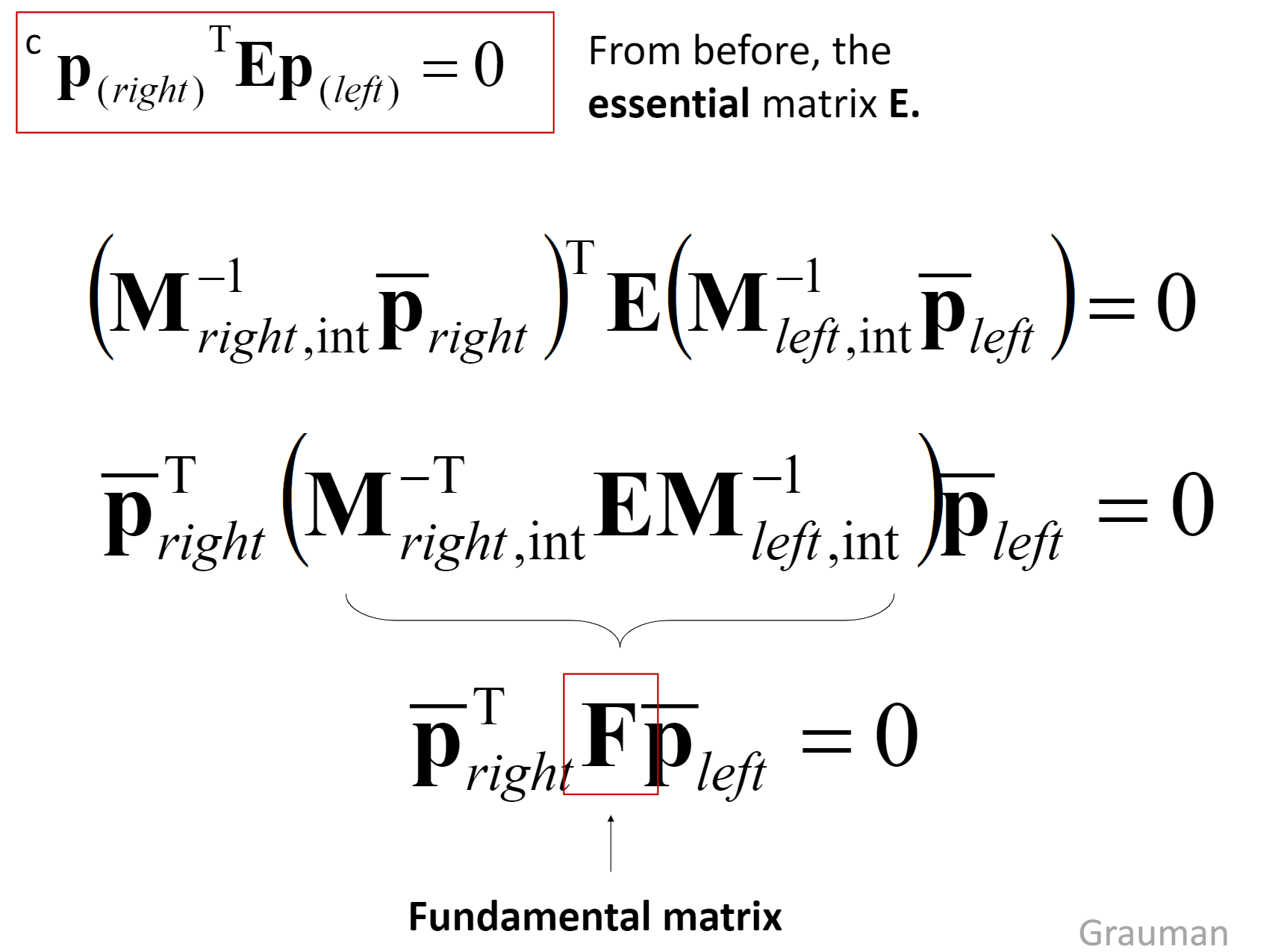
Estimate F from at least 8 corresponding points
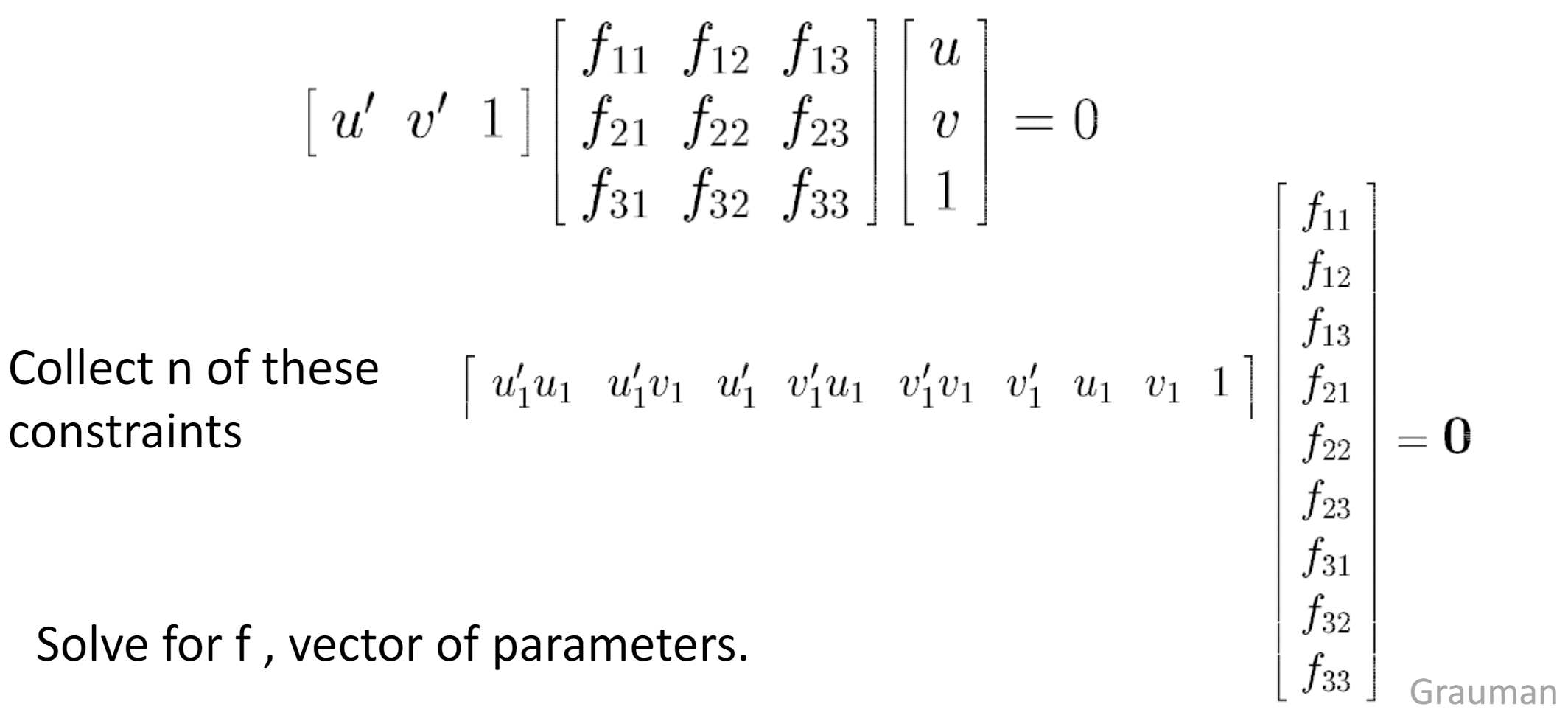
*: Rank constrain: must do SVD on F and throw out the smallest singular value to enforce rank-2 constraint
Lec 22: SFM, MVS
Problem: unknown 3D Points, Correspondences, Camera Calibration
Solution:
Feature Detection; Matching between each pair using RANSAC;
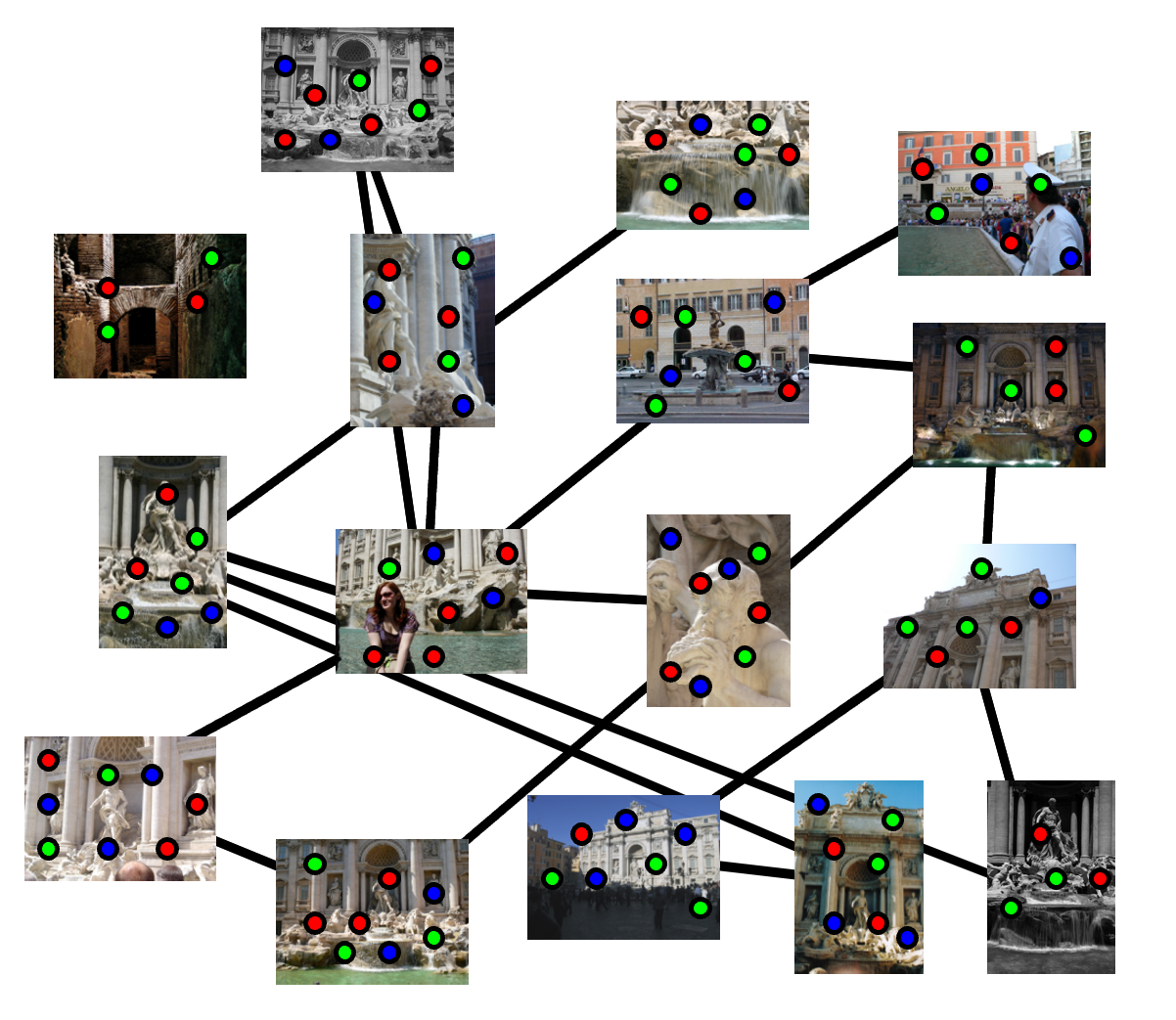
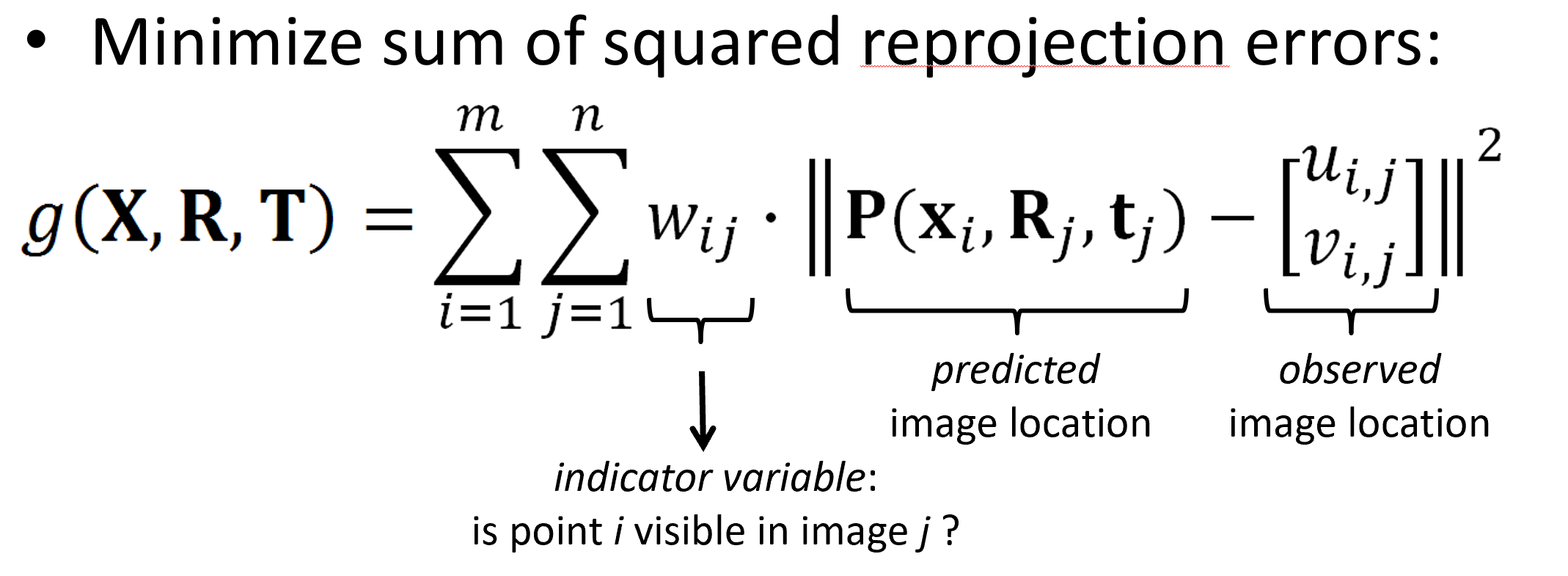
Calculate SFM using Bundle Adjustment; Optimized using non-linear least squares (E.g. Levenberg-Marquardt)

Problem: hard to init all cameras;
Solution: only start with 1/2 cameras, then grow (kind of online algorithm); "Incremental SFM"
- Choose a pair with many matches and as large a baseline as possible
- Initialize model with two-frame SFM
- While there are connected images remaining, pick one that sees the most existing 3D points; estimate pose; triangulate new points; run bundle adjustment
Appendix
- Vector cross product \[ [a_x] = \begin{bmatrix} 0 & -a_z & a_y \\ a_z & 0 & -a_x \\ -a_y & a_x & 0 \end{bmatrix} \]