
Midterm Review & Cheatsheet for CS 188 Fall 2024 | Introduction to Artificial Intelligence at UC Berkeley
Author: SimonXie2004.github.io
![]()
Resources
Lec1: Introduction
N/A
Lec2: Search
Reflex Agents V.S. Planning Agents:
- Reflex Agents: Consider how the world IS
- Planning Agents: Consider how the world WOULD BE
Properties of Agents
- Completeness: Guaranteed to find a solution if one exists.
- Optimality: Guaranteed to find the least cost path.
Definition of Search Problem:
State Space,Successor Function,Start State&Goal TestDefinition of State Space: World State & Search State
State Space Graph: Nodes = states, Arcs = successors (action results)
Tree Search
Main Idea: Expand out potential nodes; Maintain a fringe of partial plans under consideration; Expand less nodes.
Key notions: Expansion, Expansion Strategy, Fringe
Common tree search patterns (Suppose b = branching factor, m = tree depth.) Nodes in search tree? \(\sum_{i=0}^{m}b^i = O(b^m)\) (For BFS, suppose s = depth of shallowest solution) (For Uniform Cost Search, suppose solution costs \(C^*\), min(arc_cost) = \(\epsilon\))
Strategy Fringe Time Memory Completeness Optimality DFS Expand deepest node first LIFO Stack \(O(b^m)\) \(O(bm)\) True (if no cycles) False BFS Expand shallowest node first FIFO Queue \(O(b^s)\) \(O(b^s)\) True True (if cost=1) UCS Expand cheapest node first Priority Queue (p=cumulative cost) \(O(C^*/\epsilon)\) \(O(b^{C^*/\epsilon})\) True True Special Idea: Iterative Deepening Run DFS(depth_limit=1), DFS(depth_limit=2), ...
Example Problem: Pancake flipping; Cost: Number of pancakes flipped
Graph Search
- Idea: never expand a state twice
- Method: record set of expanded states where elements = (state, cost). If a node popped from queue is NOT visited, visit it. If a node popped from queue is visited, check its cost. If the cost if lower, expand it. Else skip it.
Lec3: Informed Search
Definition of heuristic: function that estimates how close a state is to a goal; Problem specific!
Example heuristics: (Relaxed-problem heuristic)
- Pancake flipping: heuristic = the number of largest pancake that is still out of place
- Dot-Eating Pacman: heuristic = the sum of all weights in a MST (of dots & current coordinate)
- Classic 8 Puzzle: heuristic = number of tiles misplaced
- Easy 8 Puzzle (allow tile to be piled intermediately): heuristic = total Manhattan distance
Remark: Can't use actual cost as heuristic, since you have to solve that first!
Comparison of algorithms:
- Greedy Search: expand closest node (to goal); orders by forward cost h(n); suboptimal
- UCS: expand closest node (to start state); orders by backward cost g(n); suboptimal
- A* Search: orders by sum f(n) = g(n) + h(n)
A* Search
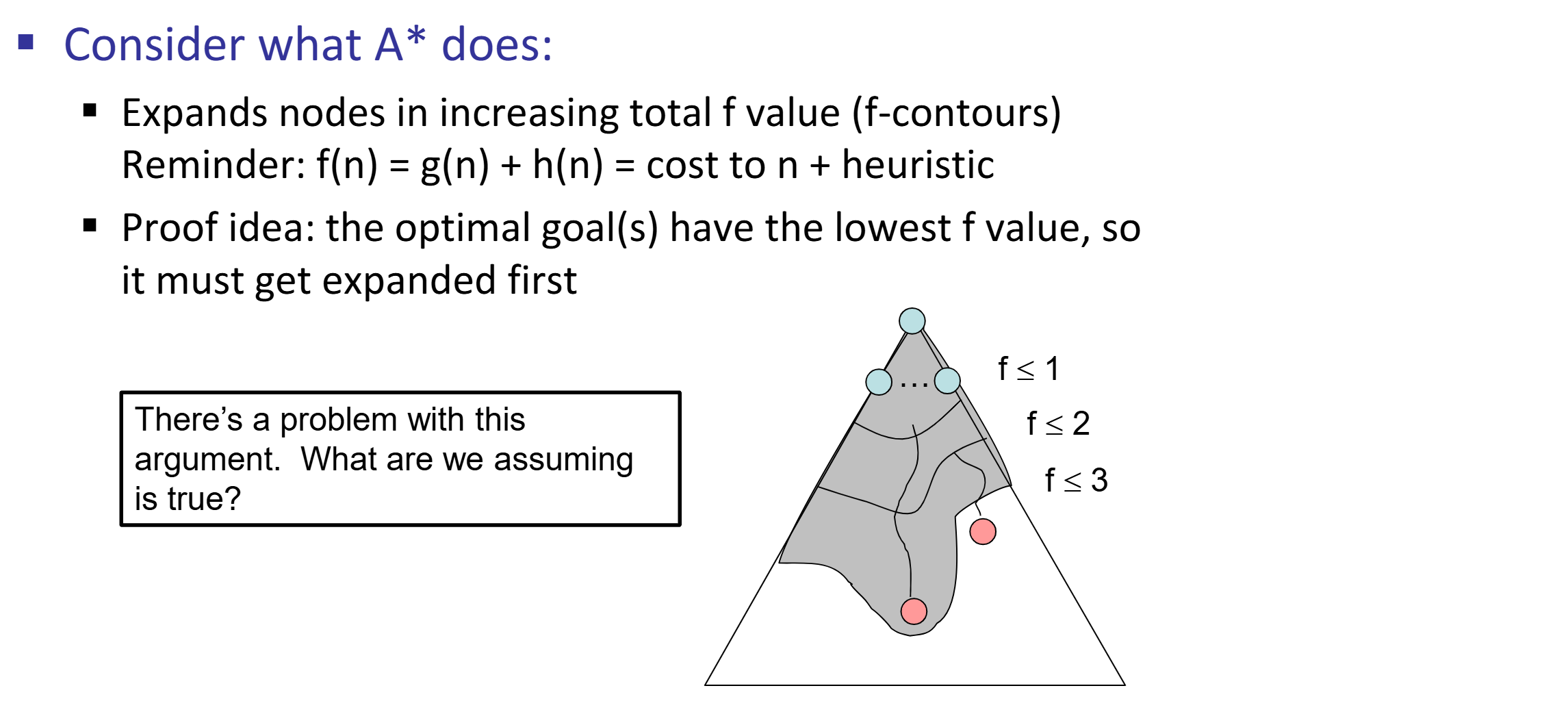
When to stop: Only if we dequeue a goal
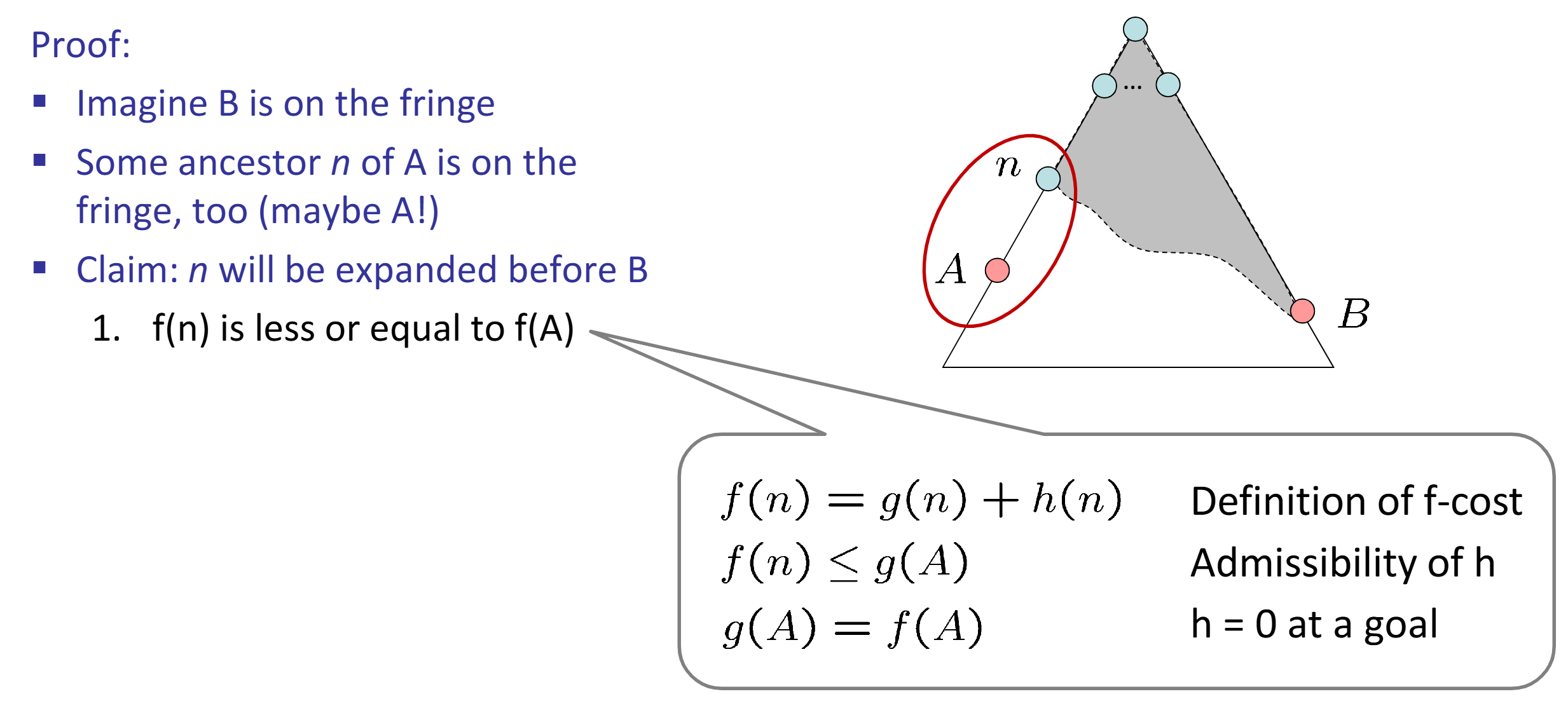
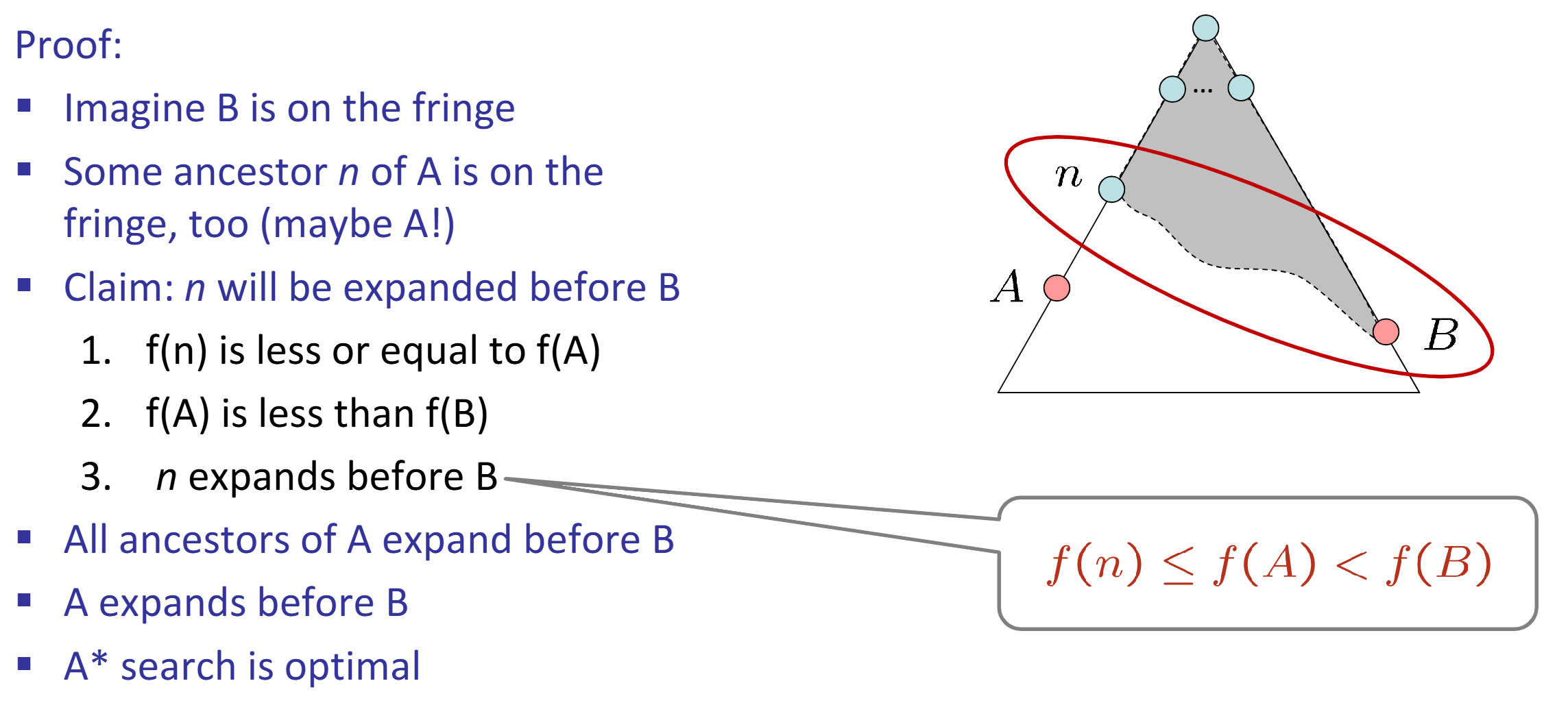
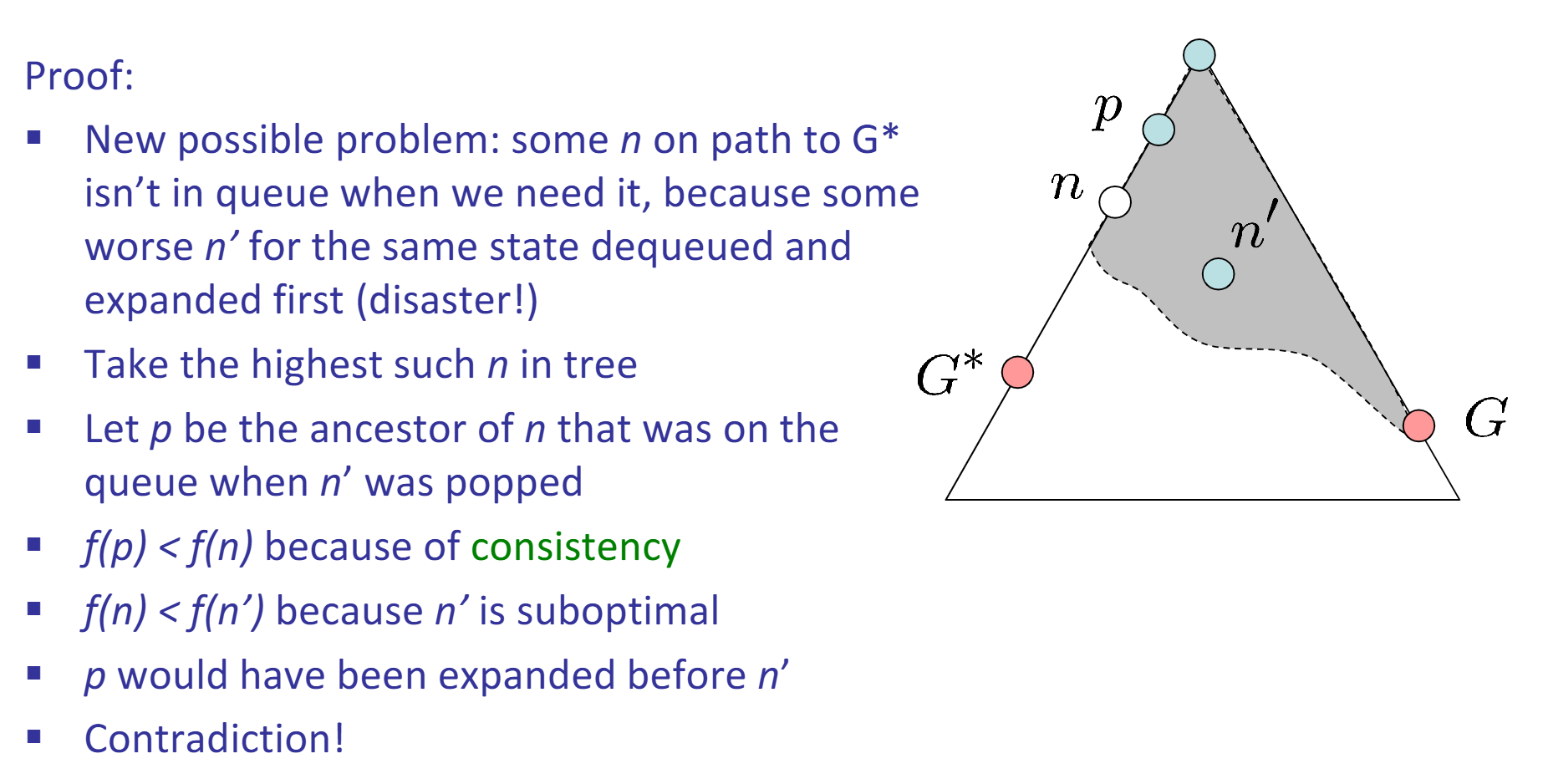
Admissible (optimistic) heuristic: \(\forall n, 0 \le h(n) \le h^*(n)\). A* Tree Search is optimal if heuristic is admissible. Proof: Step 1, Step 2.

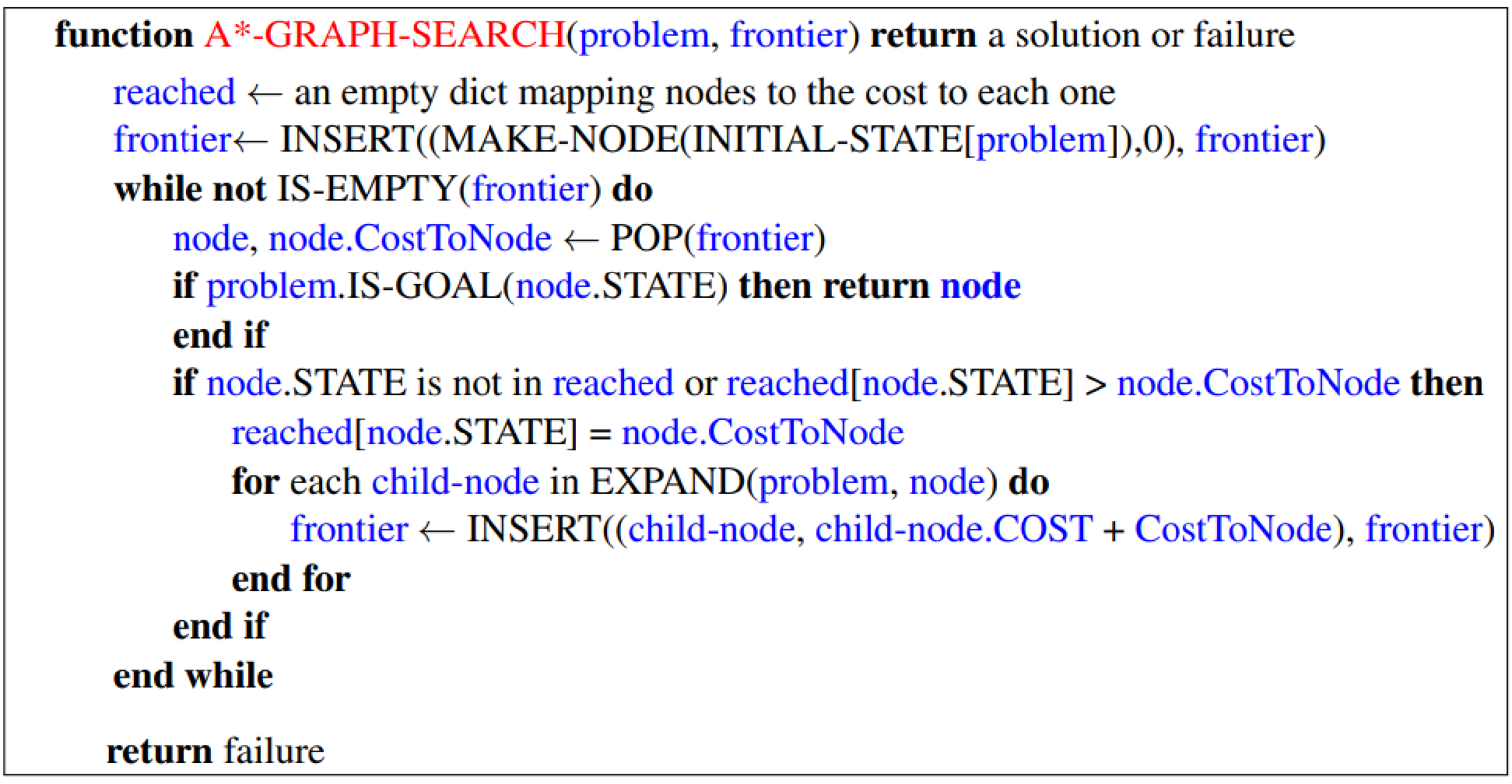
Consistent heuristic: \(\forall A, B, h(A) - h(B) \le cost(A, B)\) A* Graph Search is optimal if heuristic is consistent. Proof: Sketch, Step 1, Step 2
Semi-Lattice of Heuristics
- Dominance: define \(h_a \ge h_c\) if \(\forall n, h_a(n) \ge h_c(n)\)
- Heuristics form semi-lattice because: \(\forall h(n) = max(h_a(n), h_b(n)) \in H\)
- Bottom of lattice is zero-heuristic. Top of lattice is exact-heuristic
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Lec 4-5: Constraint Satisfaction Problems
Definition of CSP Problems: (A special subset of search problems)
- State: Varibles {Xi}, with values from domain D
- Goal Test: set of constraints specifying allowable combinations of values
Example of CSP Problems:
N-Queens
Formulation 1: Variables: Xij, Domains: {0, 1}, Constraints: \(\forall i, j, k, (X_{ij}, X_{jk}) \neq (1, 1), \cdots\) and \(\sum_{i, j}X_{ij} = N\)
Formulation 2: Variables Qk, Domains: {1, ..., N}, Constraints: \(\forall (i, j), \text{non-threatening}(Q_i, Q_j)\)
Cryptarithmetic
Constraint Graph:
- Circle nodes = Variables; Rectangular nodes = Constraints.
- If there is a relation between some variables, they are connected to a constraint node.
Simple Backtracking Search
- One variable at a time
- Check constraints as you go. (Only consider constraints not conflicting to previous assignments)
Simple Backtracking Algorithm
= DFS + variable-ordering + fail-on-violation

Filtering & Arc Consistency
Definition: Arc \(X \rightarrow Y\) is consistent if \(\forall x \in X, \exists y \in Y\) that could be assigned. (Basically X is enforcing constraints on Y)
Filtering: Forward Checking: Enforcing consistency of arcs pointing to each new assignment
Filtering: Constraint Propagation: If X loses a Value, neighbors of X need to be rechecked.
Usage: run arc consistency as a preprocessor or after each assignment
Algorithm with Runtime \(O(n^2d^3)\):

Advanced Definition: K-Consistency
K-Consistency: For each k nodes, any consistent assignment to k-1 nodes can be extended to kth node.
Example of being NOT 3-consistent:
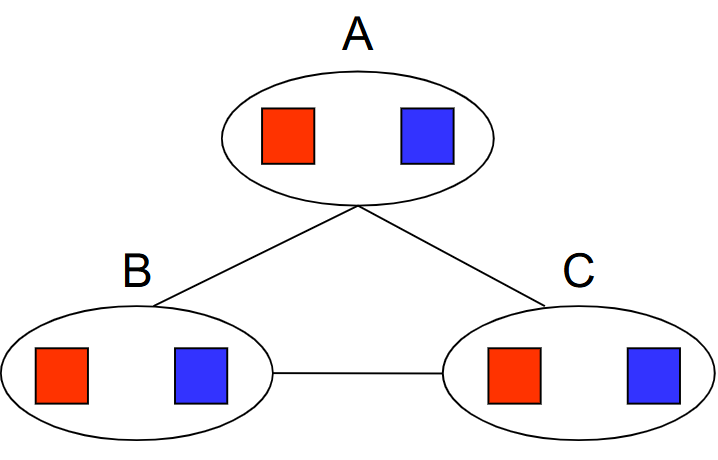
Strong K-Consistency: also k-1, k-2, ..., 1-Consistent; Can be solved immediately without searching
Problems of Arc-consistency: only considers 2-consitency
Advanced Arc-Consistency: Ordering
Variable Ordering: MRV (Minimum Remaining Value): Choose the variable with fewest legal left values in domain
Value Ordering: LCV (Least Constraining Value): Choose the value that rules out fewest values in remaining variables.
(May require re-running filtering.)
Advanced Arc-Consistency: Observing Problem Structure
Suppose graph of n variables can be broken into subproblems with c variables: Can solve in \(O(\frac{n}{c}) \cdot O(d^c)\)
Suppose graph is a tree: Can solve in \(O(nd^2)\). Method as follows
Remove backward: For i = n : 2, apply
RemoveInconsistent(Parent(Xi),Xi)Assign forward: For i = 1 : n, assign Xi consistently with Parent(Xi)
*Remark: After backward pass, all root-to-leaf are consistent. Forward assignment will not backtrack.

Advanced Arc-Consistency: Improving Problem Structure
Idea: Initiate a variable and prune its neighbors' domains.
Method: instantiate a set of vars such that remaining constraint graph is a tree (cutset conditioning)
Runtime: \(O(d^c \cdot (n-c)d^2)\) to solve CSP.
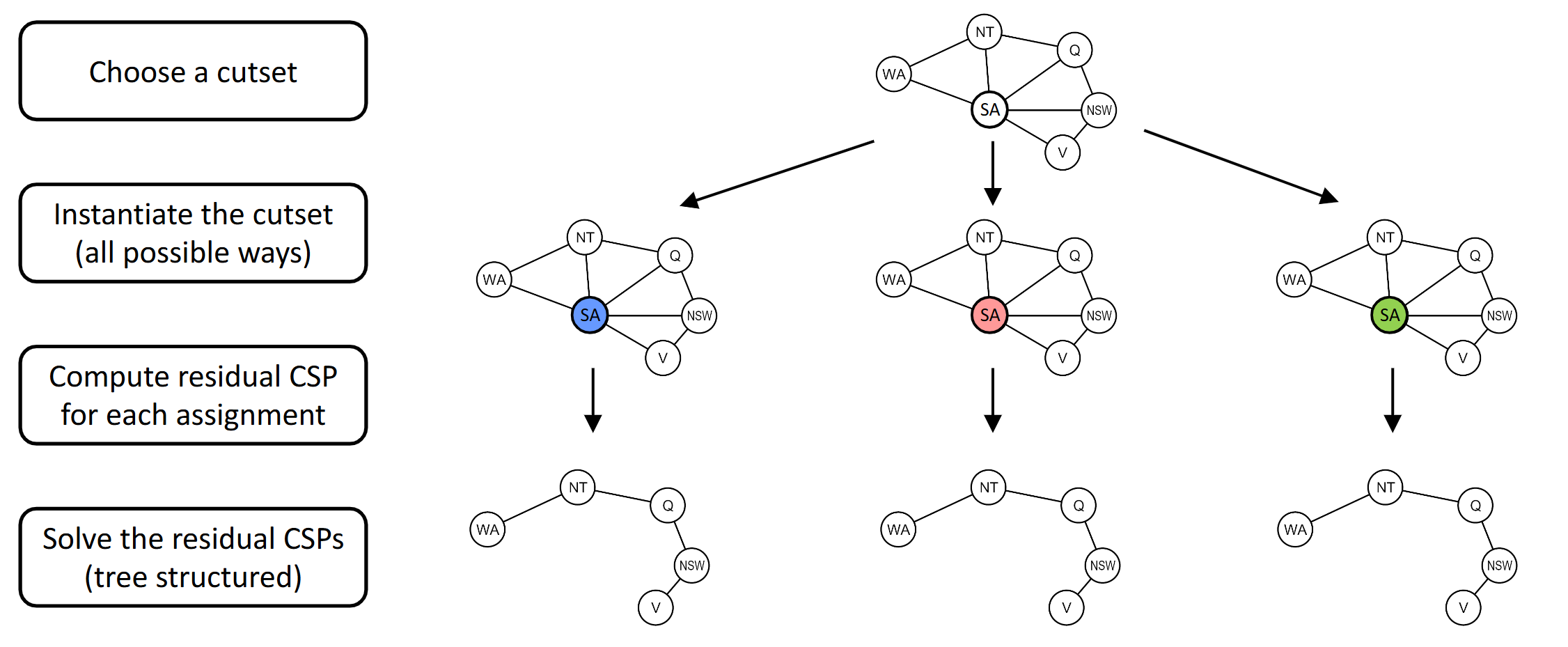
Iterative Methods: No Fringe!
Local Search
Algorithm: While not solved, randomly select any conflicted variable. Assign value by min-conflicts heuristic.
Performance: can solve n-queens in almost constant time for arbitrary n with high probability, except a few of them.
Hill-climbing

Simulated Annealing
Remark: Stationary distribution: \(p(x) \propto e^{\frac{E(x)}{kT}}\)

Genetic Algorithms
Lec 6: Simple Game Trees (Minimax)
Zero-Sum Games V.S. General Games: Opposite utilities v.s. Independent utilities
- Examples of Zero-Sum Games: Tic-tac-toe, chess, checkers, ...
Value of State: Best achievable outcome (utility) from that state.
- For MAX players, \(max_{s' \in \text{children}(s)} V(s')\); For MIN players, min...
Search Strategy: Minimax
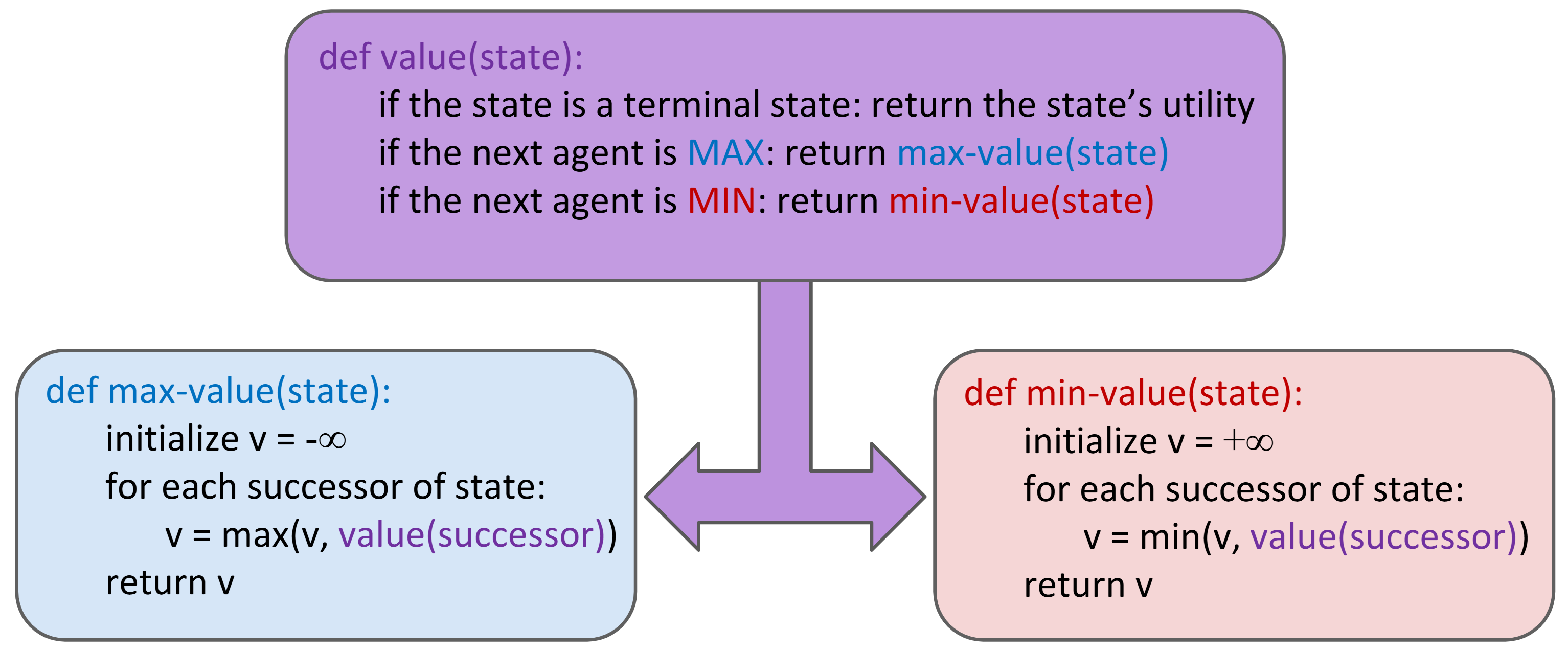
Minimax properties:
- Optimal against perfect player. Sub-optimal otherwise.
- Time: \(O(b^m)\), Space: \(O(bm)\)
Alpha-Beta Pruning
Algorithm:
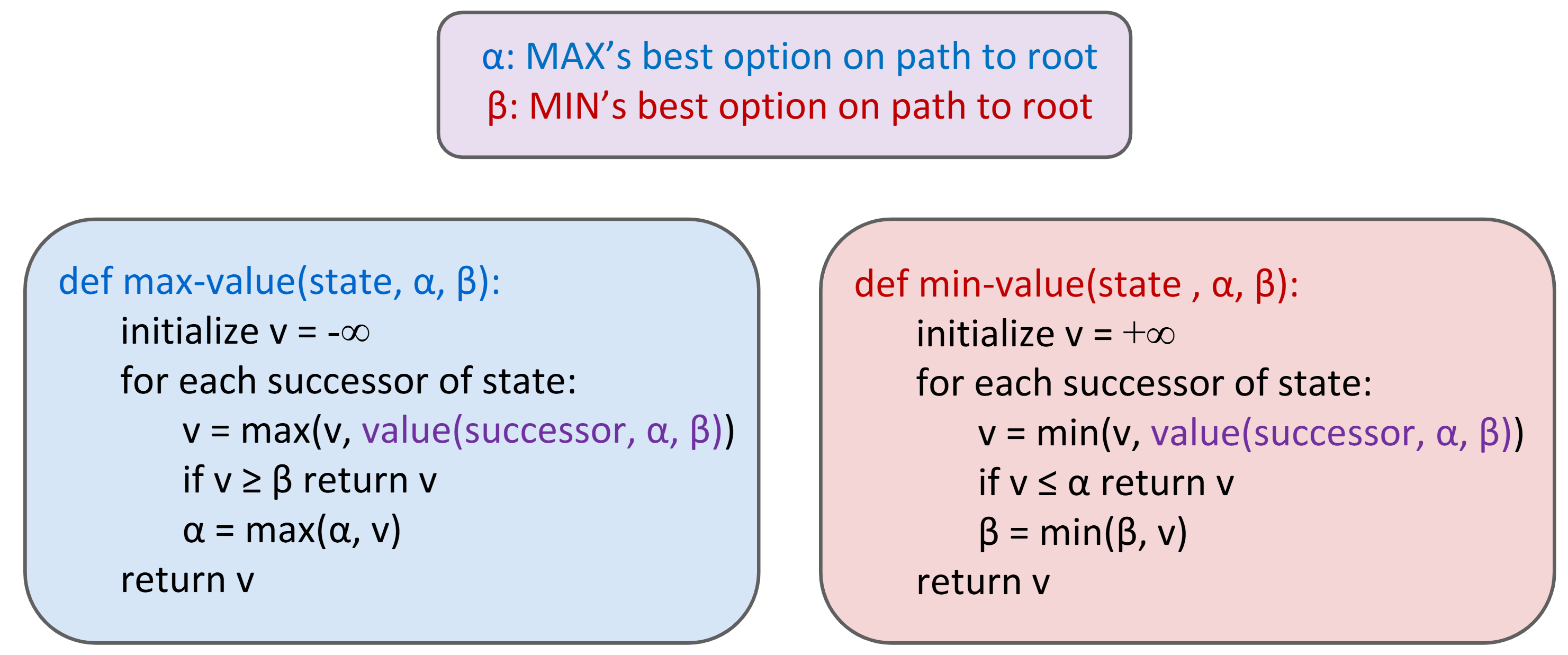
Properties:
- Meaning of Alpha: maximum reward for MAX players, best option so far for MAX player
- Meaning of Beta: minimum loss for MIN players, best option so far for MIN player
- Have no effect on root value; intermediate values might be wrong.
- With perfect ordering, time complexity drops to \(O(b^{m/2})\)
Depth-Limited Minimax: replace terminal utilities with an evaluation function for non-terminate positions
- Evaluation Functions: weighted sum of features observed
Iterative Deepening: run minimax with depth_limit = 1, 2, 3, ... until timeout
Lec 7: More Game Trees (Expectimax, Utilities, Multiplayer)
Expetimax Algorithm:
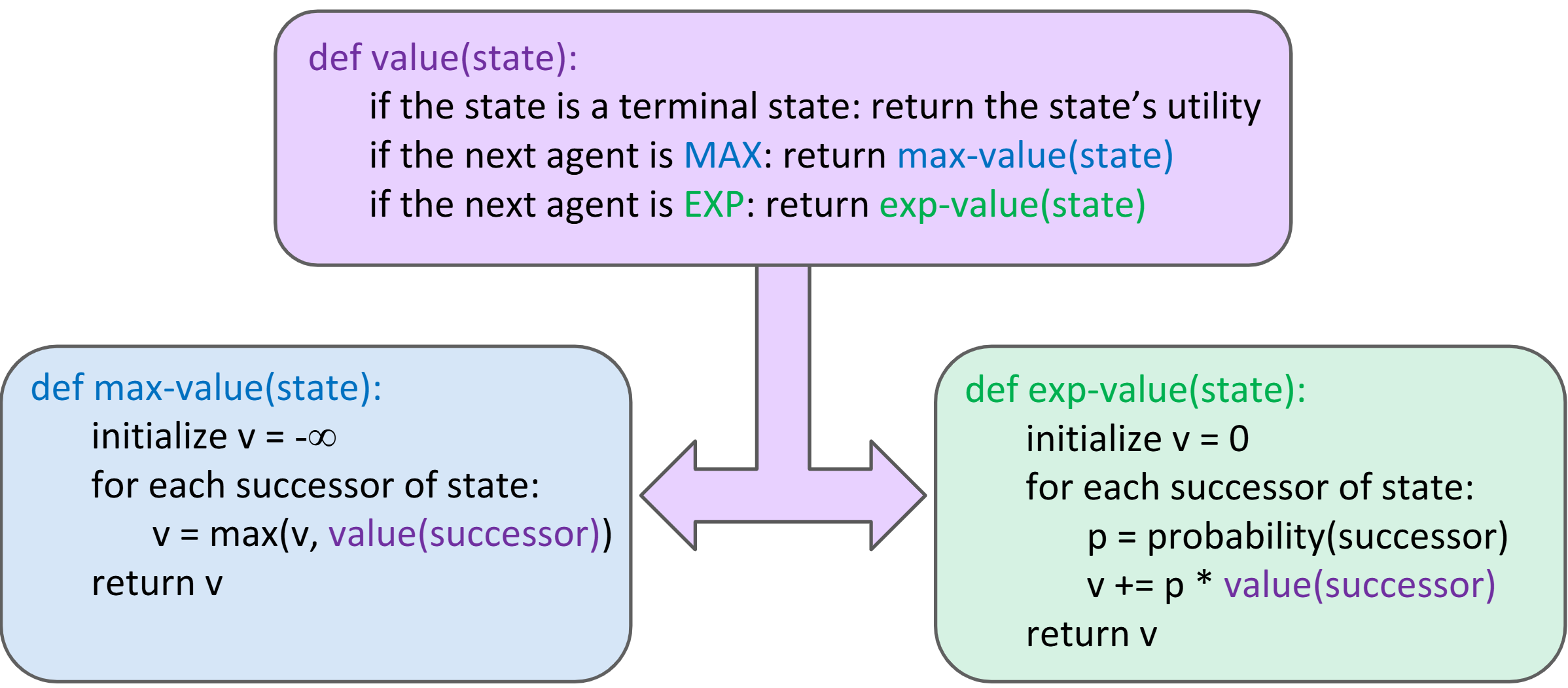
Assumptions V.S. Reality: Rational & Irrational Agents
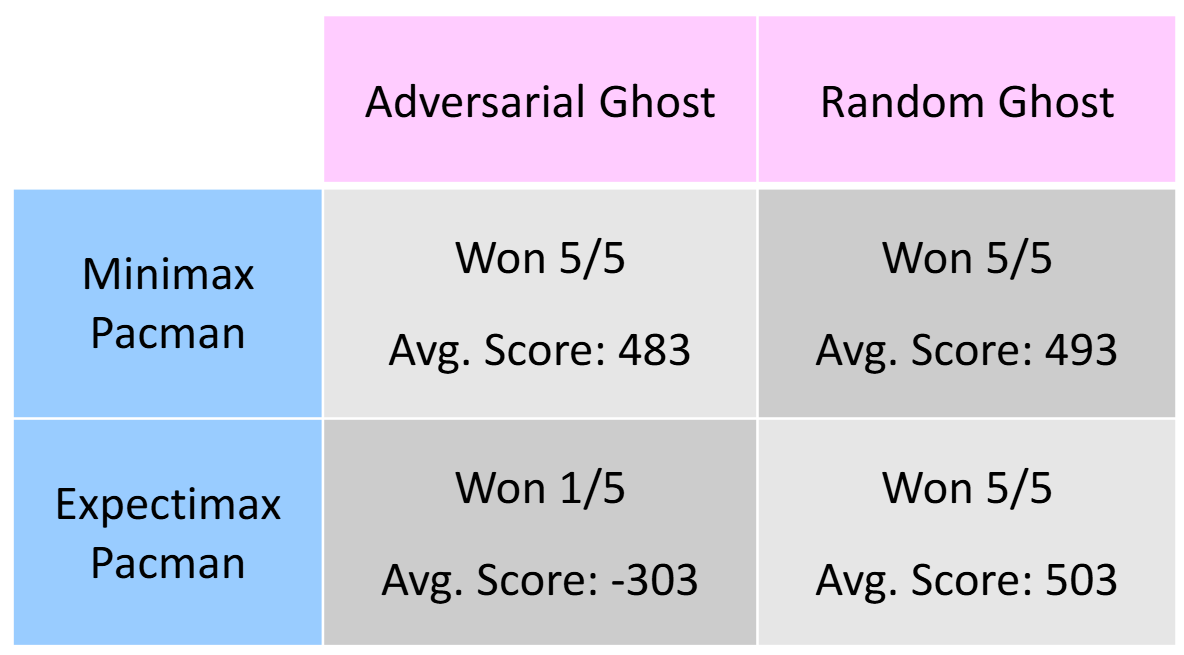
Axioms of Rationality

MEU Principle
Given any preferences satisfying these constraints, there exists a real-valued function U such that:
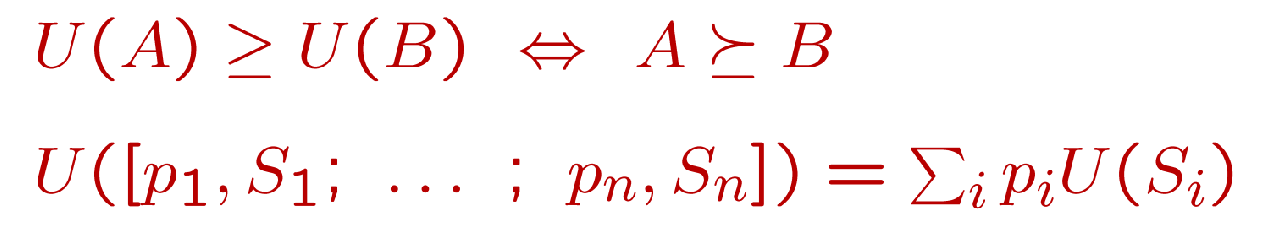
Risk-adverse v.s. Risk-prone
Def. \(L = [p, X, 1-p, Y]\)
If \(U(L) < U(EMV(L))\), risk-adverse
Where \(U(L) = pU(X) + (1-p)U(Y)\), \(U(EMV(L)) = U(pX + (1-p)Y)\)
i.e. if U is concave, like y=log2x, then risk-adverse
Otherwise, risk-prone.
i.e. if U is convex, like y=x^2, then risk-prone
Lec 8-9: Markov Decision Processes
MDP World: Noisy movement, maze-like problem, receives rewards.
- "Markov": Successor only depends on current state (not the history)
MDP World Definition:
- States, Actions
- Transition Function \(T(s, a, s')\) or \(Pr(s' | s, a)\), Reward Function \(R(s, a, s')\)
- Start State, (Probably) Terminal State
MDP Target: optimal policy \(\pi^*: S \rightarrow A\)
Discounting: Earlier is Better! No infinity rewards!
- \(U([r_0, \cdots, r_\inf]) = \sum_{t=0}^\inf \gamma^tr_t =\le R_{\text{max}} / (1-\gamma)\)
MDP Search Trees:
Value of State: expected utility starting in s and acting optimally.
\(V^*(s) = \max_a Q^*(s, a)\)
Value of Q-State: expected utility starting out having taken action a from state s and (thereafter) acting optimally.
\(Q^*(s, a) = \sum_{s'}T(s, a, s')[R(s, a, s' + \gamma V^*(s'))]\)
Optimal Policy: \(\pi^*(s)\)
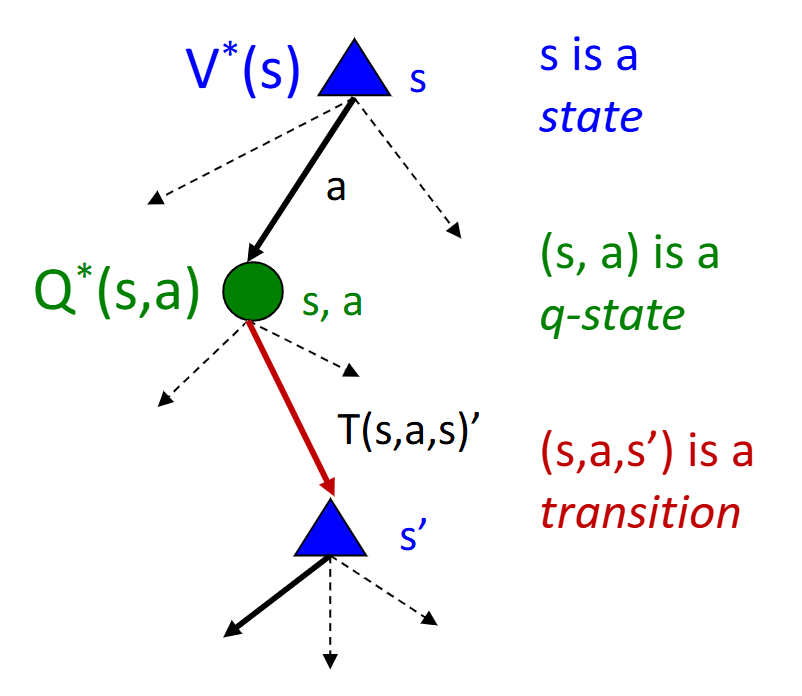
Solving MDP Equations: Value Iteration
- Bellman Equation: \(V^*(s) = \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V(s')]\)
- Value Calculation: \(V_{k+1}(s) \leftarrow \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V_k(s')]\)
- Policy Extraction: \(\pi^*(s) = \arg \max_{a} \sum_{s'} T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\)
- Complexity (of each iteration): \(O(S^2A)\)
- Must converge to optimal values. Policy may converge much earlier.
Solving MDP Equations: Q-Value Iteration
- Bellman Equation: \(Q^*(s, a) = \sum_{s'} T(s, a, s') [R(s, a, s' + \gamma \max_{a'} Q^*(s', a'))]\)
- Policy Extraction: \(\pi^*(s) = \arg \max_{a} Q^*(s, a)\)
MDP Policy Evalutaion: Evaluating V for fixed policy \(\pi\)
- Idea 1: remove the max'es from Bellman, iterating \(V_{k+1}(s) \leftarrow \sum_{s'}T(s, \pi(s), s')[R(s, \pi(s), s') + \gamma V_k(s')]\)
- Idea 2: is a linear system. Use a linear system solver.
Solving MDP Equations: Policy Iteration
Idea: Update Policy & Value meanwhile, much much faster!
Algorithm:

Lec 10-11: Reinforcement Learning
Intuition: Suppose we know nothing about the world. Don't know T or R.
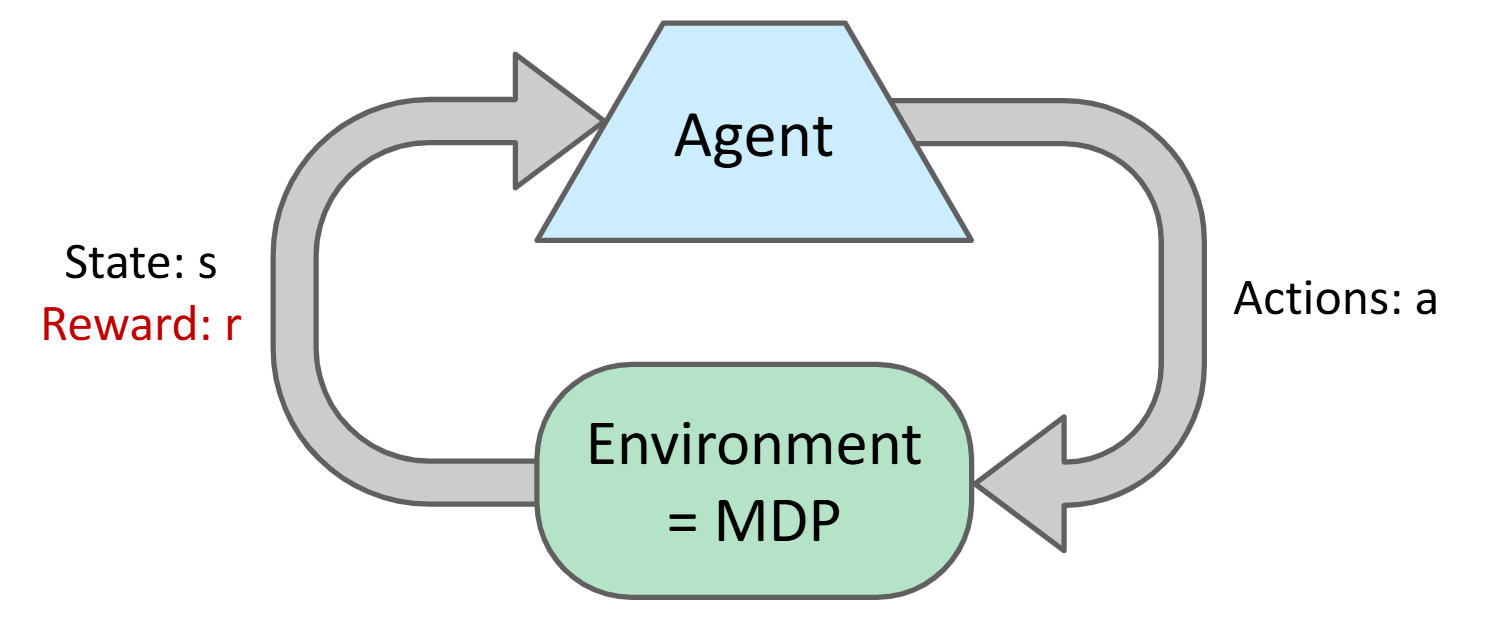
Passive RL I: Model-Based RL
- Count outcomes s' for each s, a; Record R;
- Calculate MDP through any iteration
- Run policy. If not satisfied, add data and goto step 1
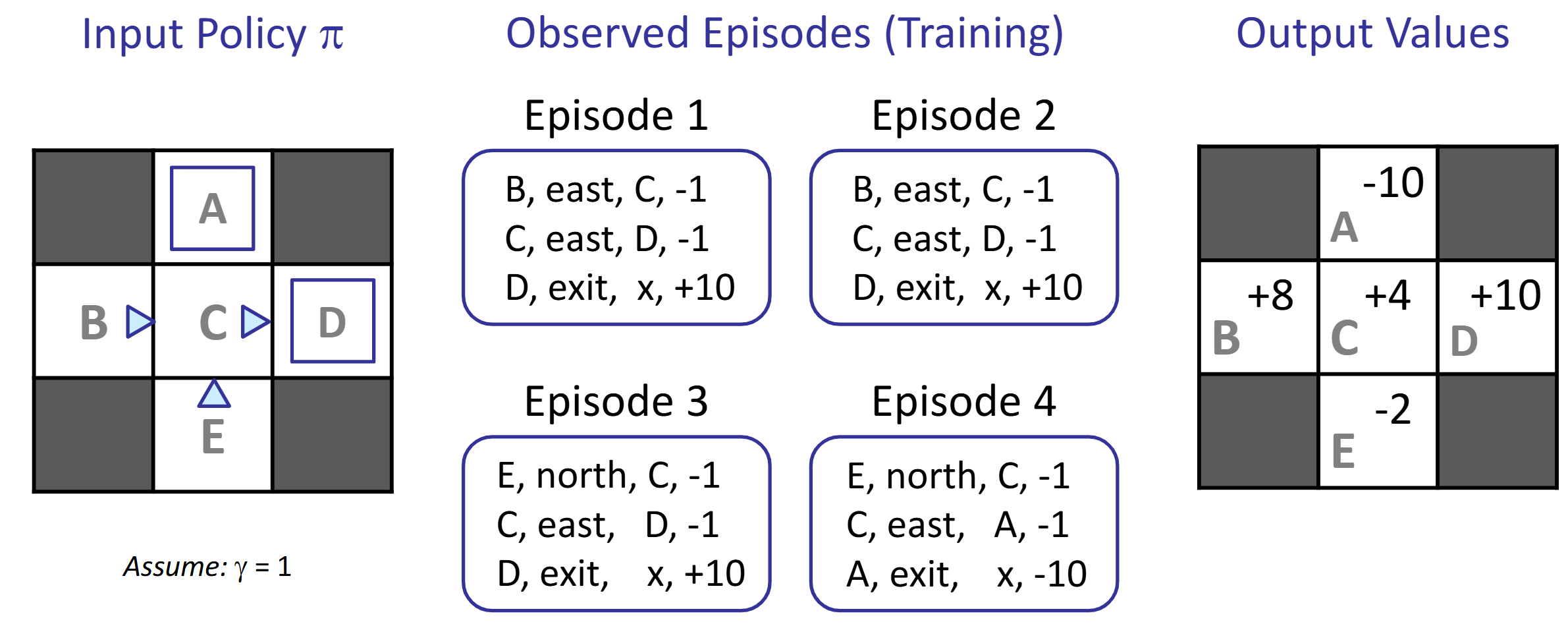
Passive RL II: Model-Free RL (Direct Evaluation, Sample-Based Bellman Updates)
Intuition: Direct evaluation from samples. improve our estimate of V by computing averages of samples.
Input: fixed policy \(\pi(s)\)
Act according to \(\pi\). Each time we visit a state, write down what the sum of discounted rewards turned out to be.
Average the samples, we get estimate of \(V(s)\)
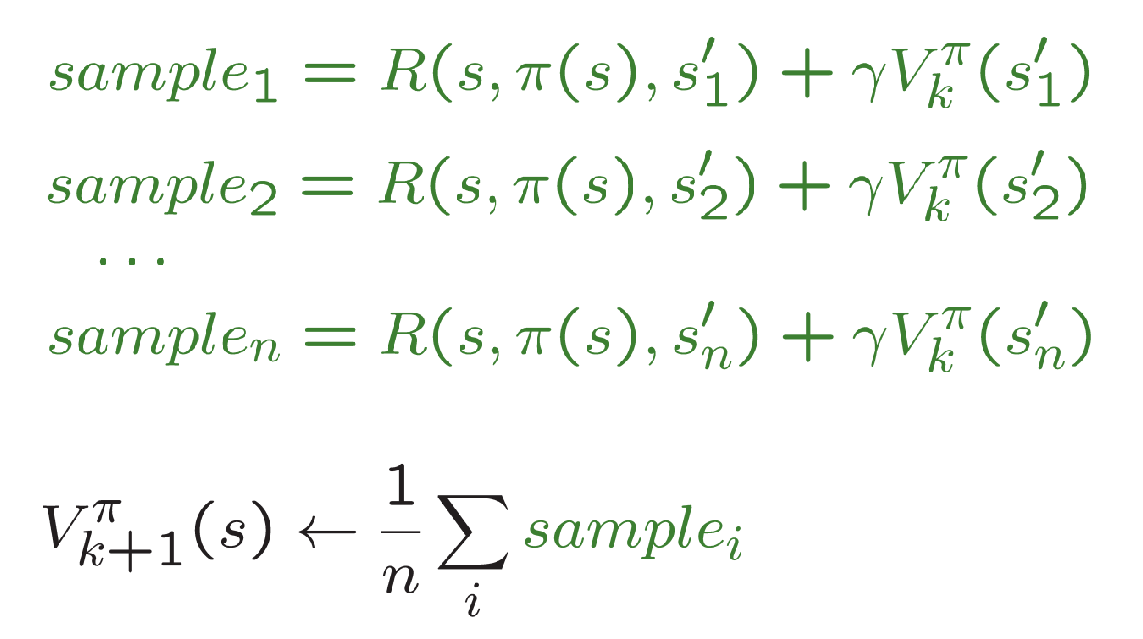
Problem: wastes information about state connections. Each state learned separately. Takes long time.
Passive RL II: Model-Free RL (Temporal Difference Learning)
Intuition: learn from everywhere / every experience.
Recent samples are more important. \(\hat{x}_n = (1-a) x_{n-1} + ax_n\)
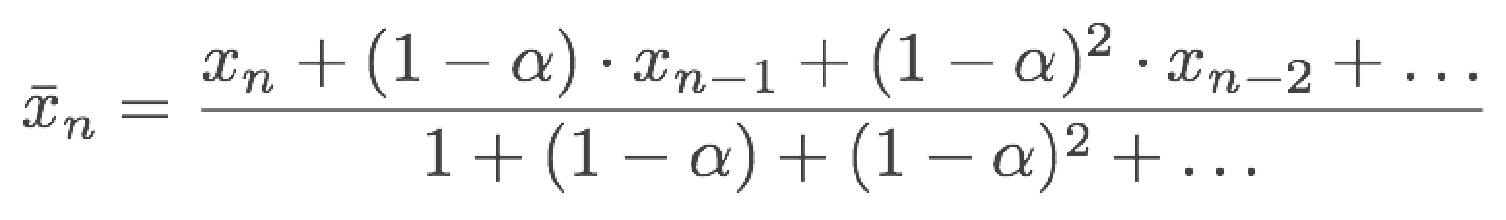
Update:
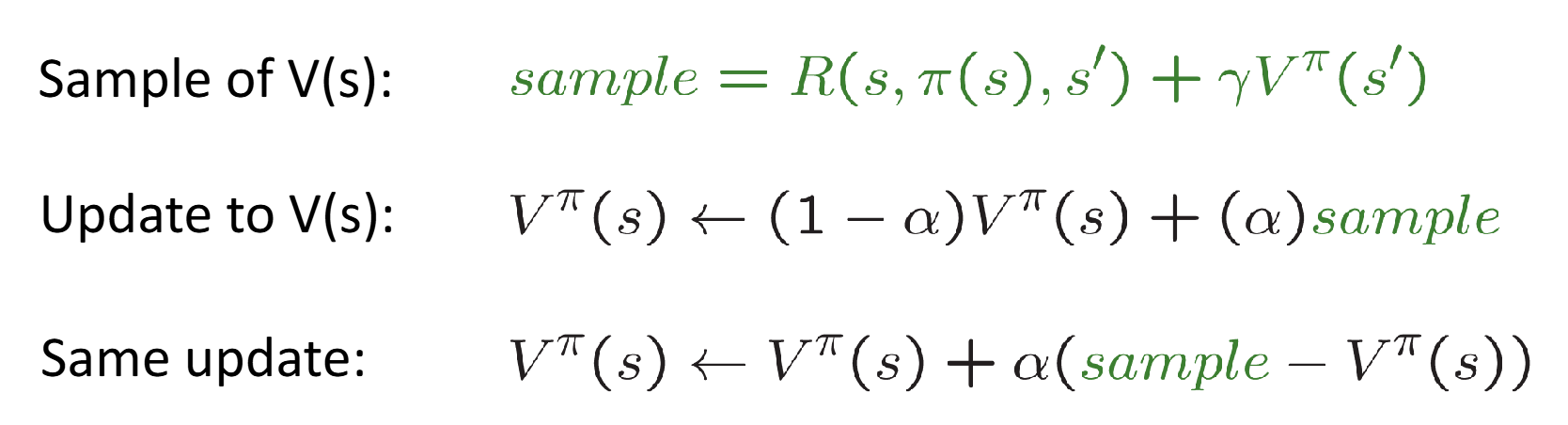
Decreasing learning rate (alpha) converges
Problem: Can't do policy extraction, can't calculate \(Q(s, a)\) without T or R
Idea: learn Q-values directly! Make action selection model-free too!
Passive RL III: Model-Free RL (Q-Learning + Time Difference Learning)
- Intuition: Learn as you go.
- Update:
- Receive a sample (s, a, s', r)
- Let sample = \(R(s, a, s') + \gamma \max_{a'} Q(s', a')\)
- Incorporate new estimate into a running average: \(Q(s, a) \leftarrow (1 - a) Q(s,a) + a \cdot \text{sample}\)
- Another representation: \(Q(s, a) \leftarrow Q(s, a) + a \cdot \text{Difference}\) where diff = sample - orig
- This is off-policy learning!
Active RL: How to act to collect data
- Exploration schemes: eps-greedy
- With probability \(\epsilon\), act randomly from all options
- With probability \(1 - \epsilon\), act on current policy
- Exploration functions: use an optimistic utility instead of real
utility
- Def. optimistic utility \(f(u, n) = u + k / n\), suppose u = value estimate, n = visit count
- Modified Q-Update: \(Q(s, a) \leftarrow_a R(s, a, s') + \gamma \max_{a'} f(Q(s', a'), N(s', a'))\)
- Measuring total mistake cost: sum of difference between expected rewards and suboptimality rewards.
- Exploration schemes: eps-greedy
Scaling up RL: Approximate Q Learning
State space too large & sparse? Use linear functions to approximately learn \(Q(s,a)\) or \(V(s)\)
Definition: \(Q(s, a) = w_1f_1(s, a) + w_2f_2(s, a) + ...\)
Q-learning with linear Q-fuctions:
Transition := (s, a, r, s')
Difference := \([r + \gamma \max_{a'}Q(s', a')] - Q(s, a)\)
Approx. Update weight: \(w_i \leftarrow w_i + a \cdot \text{Difference} \cdot f_i(s, a)\)
Lec 12: Probability
N/A
Lec 13: Bayes Nets
N/A